
Este libro incluye una serie de herramientas computacionales que facilita la implementación de los modelos para la evaluación de la susceptibilidad/amenaza por movimientos en masa. Todas estas herramientas son de código abierto (open-source), lo que significa que los creadores del software tienen disponible los códigos fuentes para que las personas los utilicen, estudien, modifiquen y redistribuyan. Esto ha permitido crear un ecosistema que hoy representa la mejor opción para computación científica. Gracias a esto, este libro guía puede ser elaborado con herramientas completamente libres que se púeden instalar en cualquier computador.
Para mayor informacion relacionada con código abierto y libre, puede consultar los siguientes links:
[Video]: resumen corto de código abierto.
[Libro] The Cathedral and the Bazaar: libro sobre los beneficios e historia del software de código abierto.
Python#
La mayor parte del curso se basa en el lenguaje de programación Python. Python es un lenguaje de programación de alto nivel ampliamente utilizado en la actualidad. Python es un lenguaje extremadamente útil para aprender en términos de GIS, ya que muchos (o la mayoría) de los diferentes paquetes de software GIS (como ArcGIS, QGIS, PostGIS, etc.) brindan una interfaz para realizar análisis utilizando secuencias de comandos de Python. Durante este curso, nos centraremos principalmente en realizar análisis geoespaciales sin software de terceros como ArcGIS. ¿Por qué? Hay varias razones para hacerlo usando Python sin ningún software adicional:
Todo es gratis: no necesita comprar una licencia costosa para ArcGIS (por ejemplo)
Aprenderá y comprenderá mucho más profundamente cómo funcionan las diferentes operaciones de geoprocesamiento
Python es altamente eficiente: se utiliza para analizar Big Data
Python es muy flexible: admite todos los formatos de datos que puedas imaginar
El uso de Python (o cualquier otro lenguaje de programación de código abierto) admite software/códigos de código abierto y ciencia abierta al hacer posible que todos reproduzcan su trabajo, sin cargo.
Complemente y encadene diferentes softwares de terceros para construir, tal como las aplicaciones GIS web sofisticadas que desee (ArcGIS, QGIS, PostGIS)
Este curso utiliza Python porque se ha perfilado como una de las principales y más sólidas opciones para Data Science, junto con otras alternativas gratuitas como R. Python es ampliamente utilizado para el procesamiento y análisis de datos tanto en la academia como en la industria. Existe una comunidad científica vibrante y en crecimiento, que trabaja tanto en universidades como en empresas, que respalda y mejora sus capacidades para el análisis de datos al proporcionar extensiones nuevas y perfeccionar las existentes (también conocidas como bibliotecas). En el mundo geoespacial, Python también se adopta ampliamente, siendo el lenguaje seleccionado para secuencias de comandos tanto en ArcGIS como en QGIS. Todo esto significa que, ya sea que esté pensando en continuar en la educación superior o tratando de encontrar un trabajo en la industria, Python será un activo importante que los empleadores valorarán significativamente.
Al ser un lenguaje de alto nivel, el código se puede “interpretar dinámicamente”, lo que significa que se ejecuta sobre la marcha sin necesidad de compilarlo. Esto contrasta con los lenguajes de programación de “bajo nivel”, que primero deben convertirse en código de máquina (es decir, compilarse) antes de que puedan ejecutarse. Con Python, uno no necesita preocuparse por la compilación y puede simplemente escribir código, evaluarlo, corregirlo, reevaluarlo, etc. en un ciclo rápido, lo que la convierte en una herramienta muy productiva.
Si desea instalar Python, vaya a la página Python Releases y descargue el instalador ejecutable de la versión estable más reciente. Una vez completada la descarga, ejecute el instalador. En la primera página del instalador, asegúrese de seleccionar la opción “Agregar Python a PATH” y haga clic en los pasos de configuración restantes dejando todos los valores predeterminados de instalación preseleccionados.

Adicional al lenguaje de programación Python es necesario instalar paquetes que contienen funciones necesarias para las tareas a realizar. Al igual que hay muchas distribuciones de Python diferentes, también hay varios administradores de paquetes diferentes disponibles. A pesar de tener varias opciones, la mayoría de los administradores de paquetes funcionan de la misma manera y usan una estructura de comando simple. Cada distribución de Python generalmente se incluye con un administrador de paquetes específico. Algunos de los más comunes son pip y conda.
A continuación se muestra una lista de paquetes útiles (y enlaces a sus documentos) que lo ayudan a ponerse en marcha al realizar análisis de datos o GIS en Python. Si está interesado o cuando comienza a usar estos módulos en su propio trabajo, es muy recomendable leer la documentación de las páginas web del módulo que usa:
Análisis y visualización de datos:#
Numpy –> Paquete fundamental para computación científica con Python
Pandas –> Estructuras de datos y herramientas de análisis de datos fáciles de usar y de alto rendimiento
Statsmodels –> Modelos estadísticos para Python
Scikit-learn –> Aprendizaje automático para Python (clasificación, regresión, agrupamiento, etc.)
Matplotlib –> Biblioteca básica de trazado para Python
Seaborn –> Visualización de datos estadísticos
SIG:#
GDAL –> Paquete fundamental para procesar formatos de datos vectoriales y raster (muchos módulos a continuación dependen de esto). Se utiliza para el procesamiento de tramas.
Geopandas -> Trabajar con datos geoespaciales en Python es más fácil, combina las capacidades de pandas y shapely.
Shapely -> Paquete de Python para manipulación y análisis de objetos geométricos planos (basado en GEOS ampliamente implementado).
Pysal –> Biblioteca de funciones de análisis espacial escritas en Python.
GeoViews –> Mapas Interactivos para la web.
OSMnx –> Python para redes de calles. Recupere, construya, analice y visualice redes de calles desde OpenStreetMap
Cartopy -> Haga que dibujar mapas para el análisis y la visualización de datos sea lo más fácil posible.
Rasterio –> E/S raster limpia y rápida y geoespacial para Python.
Package Installer for Python (PIP)#
Pip es un administrador de paquetes que está diseñado específicamente para instalar paquetes de Python exclusivamente. Para verificar si Pip está instalado en su equipo dirijase a la linea de comandos y escriba:
pip --version
En caso de no tener instalado Pip puede descargarlo e instalarlo de su pagina web.
Para descargar e instalar paquetes de Python con Pip se debe realizar desde la linea de comandos escribiendo pip install y el nombre el paquete que se desea descargar e instalar. Por ejemplo para descargar el paquete JupyterLab que se utilizará en este libro se escribe:
pip install jupyterlab
Esta línea descarga e instala el paquete Jupyter Notebook. Una vez completado, podemos verificar que Jupyter Notebook se instaló correctamente ejecutando jupyter notebook desde la línea de comandos. Esto iniciará el servidor de Jupyter Notebook, imprimirá información sobre el servidor de notebook en la consola y abrirá una nueva pestaña del navegador en http://localhost:8888.

Conda#
Conda es un instalador de código abierto y una herramienta de administración de paquetes que también puede manejar dependencias de bibliotecas de Python y que no son de Python. Las dos distribuciones más populares son Anaconda y Miniconda. Anaconda es una distribución de Python de código abierto diseñada específicamente para la ciencia de datos, el aprendizaje automático y el procesamiento de datos a gran escala. Incluye el lenguaje Python central, más de 1500 paquetes de ciencia de datos, un sistema de administración de paquetes llamado conda, IPython (un intérprete interactivo de Python) y mucho más. Si bien es una distribución muy completa, también es bastante grande y, por lo tanto, puede tardar un poco en descargarse y consume mucho espacio en disco. Miniconda, por otro lado, es una versión reducida de Anaconda e incluye todos los mismos componentes excepto los 1500 paquetes de ciencia de datos preinstalados. En cambio, podemos simplemente instalar estos paquetes individualmente según sea necesario usando conda (el administrador de paquetes Anaconda/Miniconda).

Elige Anaconda si:
Son nuevos en conda o Python.
Como la comodidad de tener Python y más de 1500 paquetes científicos instalados automáticamente a la vez.
Tenga el tiempo y el espacio en disco—unos minutos y 3 GB.
No desea instalar individualmente cada uno de los paquetes que desea utilizar.

Elige Miniconda si:
No te preocupes por instalar cada uno de los paquetes que quieras utilizar de forma individual.
No tiene tiempo ni espacio en disco para instalar más de 1.500 paquetes a la vez.
Quiere un acceso rápido a Python y los comandos de conda y desea ordenar los otros programas más tarde.
Si prefiere Miniconda, deberá descargar e instalar Miniconda. Miniconda no tiene una interfaz para el usuario como Anaconda, debe ser a través de la línea de comando.
A continuación, el instalador le preguntará si desea hacer alguna de estas dos cosas.
Agregue “Anaconda” a mi variable de entorno “RUTA”. Dice no hacerlo bien en el texto del instalador, recomiendo revisarlo.
Registre “Anaconda” como mi entorno “predeterminado de Python 3.7”. Esto viene comprobado, y lo recomiendan.
Tanto Anaconda como Miniconda vienen con Conda. Y debido a que Conda es un administrador de paquetes, lo que puede lograr con Anaconda, puede hacerlo con Miniconda. En otras palabras, los pasos de la sección Miniconda (crear un entorno personalizado con Conda) funcionarán después de haber pasado por la sección Anaconda.
Se recomienda encarecidamente que instale la Distribución Python de Anaconda. Te hará la vida mucho más fácil. Puede descargar e instalar Anaconda en Windows, OSX y Linux.
Integrated Development Environments (IDE’s)#
Los IDE’s son aplicaciones que permiten interactuar con lenguajes de programación, pero que adicionalmente incluyen editor de código, llenado automático, revisión de errores de sintaxis, control de versiones, entre otros. Existen múltiples IDE’s para Python, entre ellos: JupyterLab, PyCharm, Visual Studio Code, Spyder.
Jupyter Lab#
La principal herramienta computacional que utilizará durante este curso es JupyterLab. Jupyter Lab es una interfaz web interactiva para el desarrollo de código, que sigue el concepto conocido como REPL (Read — Evaluate — Print — Loop), que es ampliamente utilizado por los científicos de datos. La gran ventaja de utilizar un entorno REPL es que podemos desarrollar nuestro código de forma gradual, ejecutando comando a comando y comprobando sus resultados. Además, podemos guardar texto explicativo junto con el código que vamos a desarrollar y también visualizar los resultados, todo en el mismo entorno sin necesidad de alternar entre la línea de comandos y otras aplicaciones, como el visor de imágenes u otras. Los blocs de notas son una forma conveniente de unir texto, código y la salida que produce en un solo archivo que luego puede compartir, editar y modificar. Puede pensar en los cuadernos como el documento de Word de los científicos de datos.
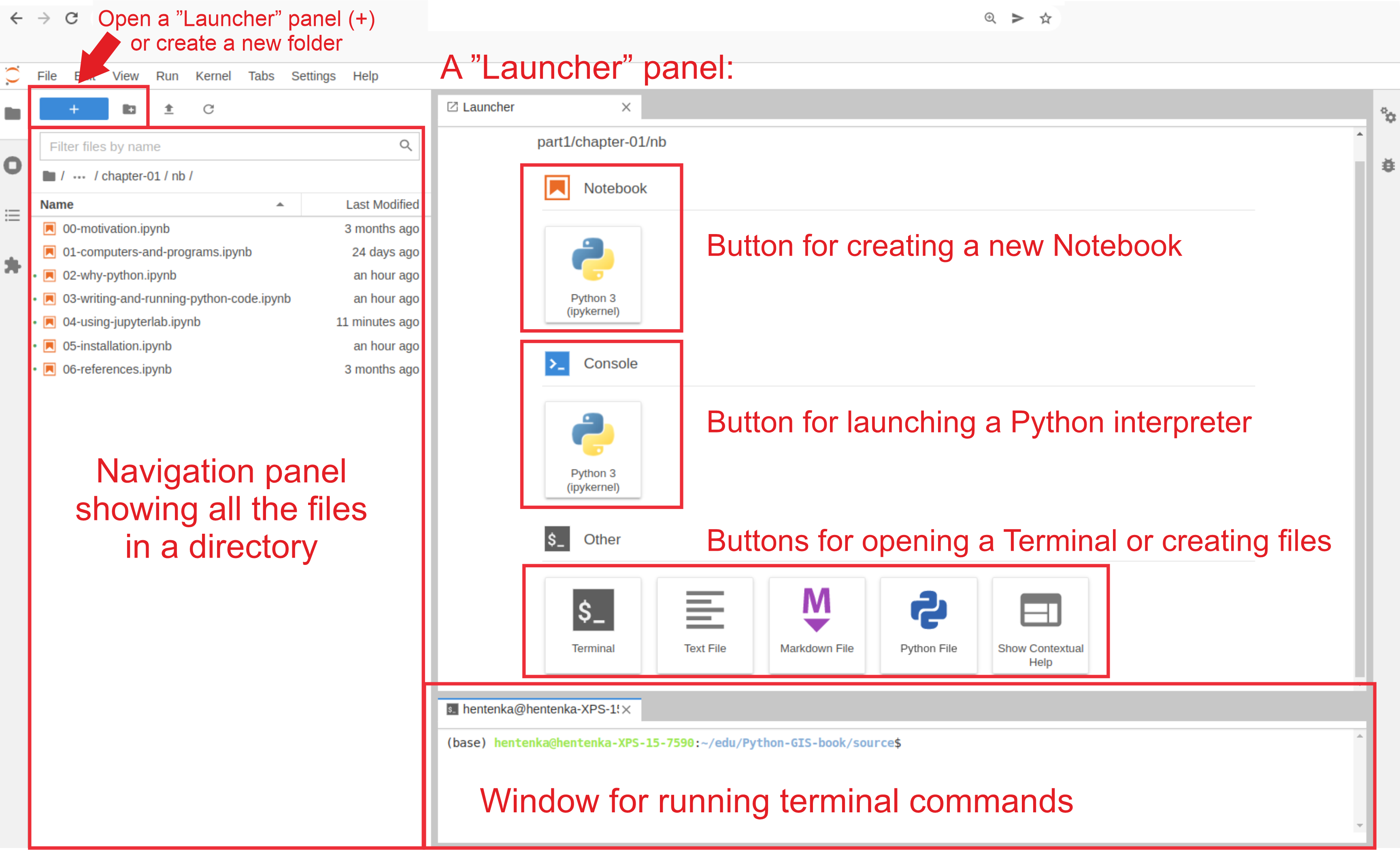
Un cuaderno consta de un solo archivo que almacena texto narrativo, código de computadora y la salida producida por el código. Almacenar tanto el trabajo narrativo como el computacional en un solo archivo significa que todo el flujo de trabajo se puede registrar y documentar en el mismo lugar, sin tener que recurrir a dispositivos auxiliares (como un cuaderno de papel). Una segunda característica de los cuadernos es que permiten el trabajo interactivo. El trabajo computacional moderno se beneficia de la capacidad de probar, fallar, modificar e iterar rápidamente hasta encontrar una solución funcional. Los portátiles encarnan esta cualidad y permiten al usuario trabajar de forma interactiva. Ya sea que la computación se realice en una computadora portátil o en un centro de datos, las computadoras portátiles brindan la misma interfaz para la computación interactiva, lo que reduce la carga cognitiva requerida para escalar. Tercero, los cuadernos tienen interoperabilidad incorporada. El formato de cuaderno está diseñado para registrar y compartir el trabajo computacional, pero no necesariamente para otras etapas del ciclo de investigación. Para ampliar la gama de posibilidades y aplicaciones, los portátiles están diseñados para ser fácilmente convertibles a otros formatos. Por ejemplo, si bien se requiere una aplicación específica para abrir y editar la mayoría de los formatos de archivo de notebook, no se requiere software adicional para convertirlos en archivos pdf que se pueden leer, imprimir y anotar sin necesidad de software técnico.
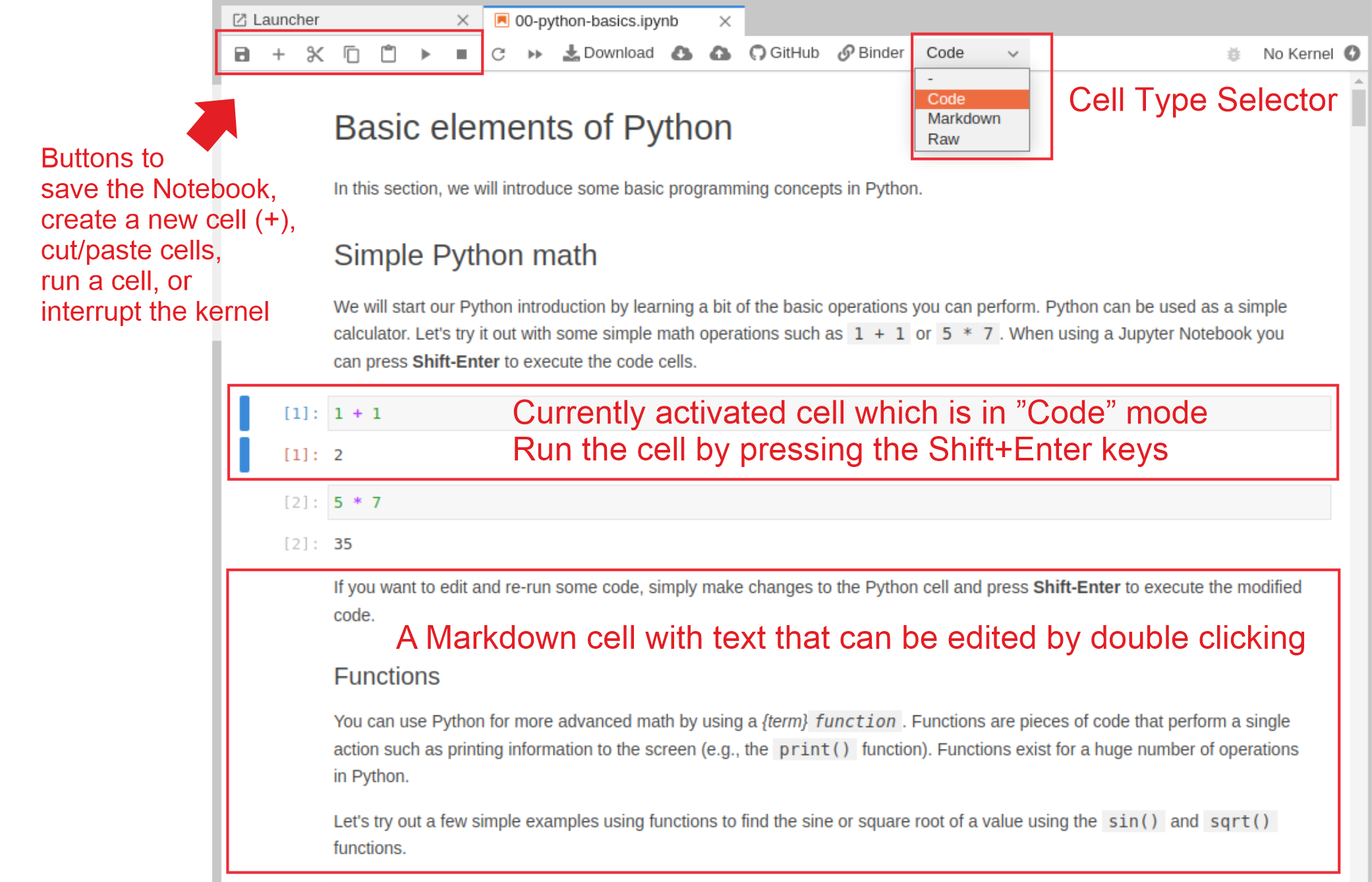
Un cuaderno de Jupyter es un archivo de texto sin formato con la extensión .ipynb, lo que significa que es un archivo fácil de mover, sincronizar y rastrear a lo largo del tiempo. Internamente, está estructurado como un documento de texto sin formato que contiene notación de objetos de JavaScript que registra el estado del cuaderno, por lo que también se integra bien con una gran cantidad de tecnologías web modernas. El elemento atómico que compone un cuaderno se llama célula. Las celdas son fragmentos consistentes de contenido que contienen texto o código. De hecho, un cuaderno puede considerarse como una colección ordenada de celdas. Las celdas pueden ser de dos tipos: texto y código.
Estos archivos se han convertido en una excelente herramienta para realizar códigos en un formato de escritura tipo Markdown. Estos archivos pueden trabajarse con Jupyter, Jupyter Lab o Google Colab.
Los bloques de los cuadernos corresponden a celdas. Las cuales pueden ser de dos tipos:
Texto
Codigo
Las celdas de texto en un cuaderno están en un lenguaje Github Flavored Markdown. Lo que significa que se debe escribir en texto plano con algunas reglas simples y el notebook mostrar el texto correspondiente interpretando las reglas insertadas para editar el texto.
Creación de un entorno#
Antes de comenzar con JupyterLab, se recomienda crear un entorno para el proyecto. Los entornos pueden considerarse repositorios en los que se instalan paquetes de Python para evitar conflictos entre paquetes y versiones. Por ejemplo, si tiene un código desarrollado con un paquete NumPy 1.18 y este código no funciona con la versión actual, que es la 1.20, puede (y debe) crear entornos específicos para cada versión.
Conda viene inicialmente con un entorno estándar llamado base (raíz). En Anaconda se crea un nuevo entorno haciendo clic en la pestaña Entornos a la izquierda y en el botón Crear debajo de la lista de entornos. A este nuevo entorno, podemos darle cualquier nombre como “cartogeotecnia” y seleccionar una version de Python como paquete principal.
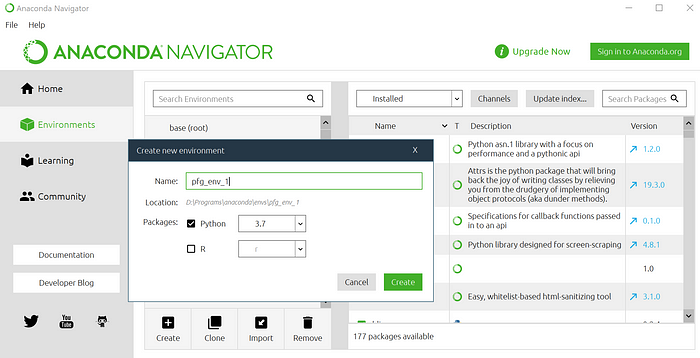
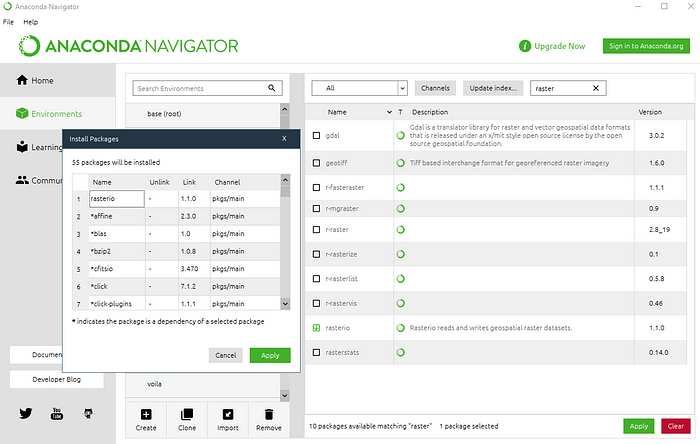
Para instalar un nuevo paquete en dicho entorno, es necesario buscar el nombre del paquete deseado usando la barra de búsqueda (no olvide seleccionar Todo en el cuadro desplegable), seleccione el paquete de la lista y haga clic en Aplicar. Como los paquetes funcionan con dependencias, dependiendo del paquete a instalar, instalará todos los paquetes necesarios que aún no existen en el entorno actual.
En Miniconda para crear un nuevo entorno, en este caso se llamará carto, se utiliza el siguiente comando:
conda create --name carto
Para activar un entorno desde la línea de comandos se digita:
conda activate carto
De igual forma para desactivar un entorno se utiliza:
conda deactivate carto
Es posible crear un entorno con un archivo de configuración, donde se especifique directamente en la creación del entorno los paquetes que se quieren instalar. Para esto se puede utilizar un archivo .yml. En este archivo se puede especificar la version de Python y los paquetes con sus versiones deseadas, al igual que el canal de conda que se desea utilizar para descargar los paquetes, generalmente se recomienda utilizar conda-forge.
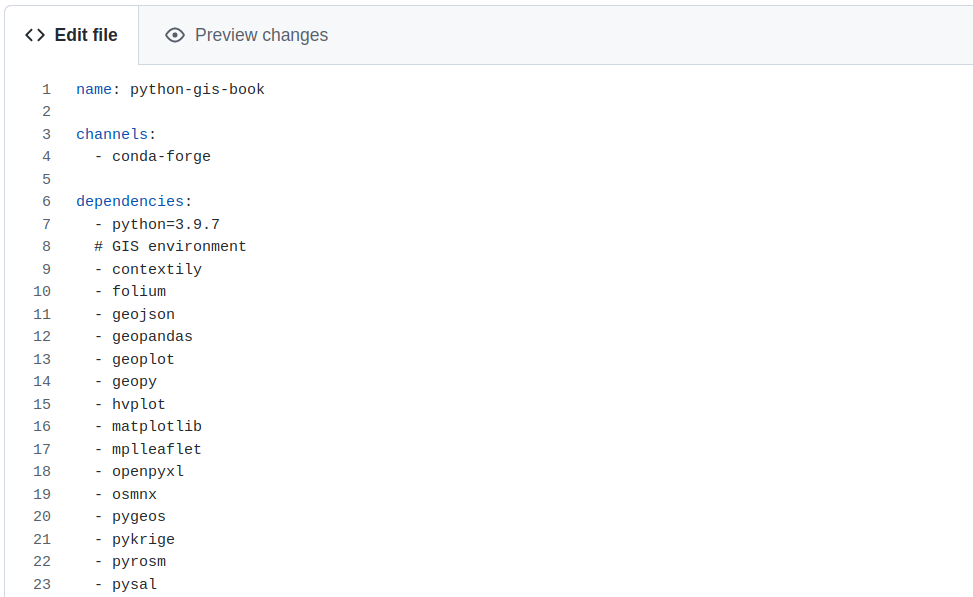
Con un archivo de configuraciónn denominado en este caso environment.yml se procede en la línea de comandos a escribir:
conda create -f enviroment.yml
Agregar entorno virtual a JupyterLab#
Jupyter Notebook se asegura de que el kernel de IPython esté disponible, pero debe agregar manualmente un kernel con una versión diferente de Python o un entorno virtual. Primero, asegúrese de que su entorno esté activado con conda active myenv. A continuación, instale ipykernel que proporciona el kernel de IPython para Jupyter:
pip install --user ipykernel
A continuación, puede agregar su entorno virtual a Jupyter escribiendo:
python -m ipykernel install --user --name=myenv
Donde myenv es el nombre del ambiente. Cuando por alguna razón elimina su entorno virtual, y quiera eliminarlo también de Jupyter puede escribir:
jupyter kernelspec desinstalar myenv
Para instalar Jupyter Lab en el ambiente creado se puede utilizar:
conda install -c conda-forge jupyterlab
Para abrir Jupyter simplemente digite dentro de su ambiente activado :
jupyter lab
Se deberá abrir una página web en el servidor local con Jupyter Lab. Para manterner el kernel funcionando se deberá mantener la página del cmd donde se abrió Jupyter Lab.
Material adicional#
En los siguientes enlaces puede encontrar material para mejorar sus conociientso de Python: