Créditos: El contenido de este cuaderno ha sido tomado de varias fuentes, pero especialmente de Dani Arribas-Bel - University of Liverpool & Sergio Rey - Center for Geospatial Sciences, University of California, Riverside. El compilador se disculpa por cualquier omisión involuntaria y estaría encantado de agregar un reconocimiento.
Regresión Espacial#
Objetivos de aprendizaje#
Al finalizar este notebook, el estudiante será capaz de:
Diagnosticar la presencia de autocorrelación espacial en residuos de un modelo OLS.
Comprender las consecuencias estadísticas de ignorar la dependencia espacial en la regresión.
Ajustar modelos de regresión con dependencia en la variable dependiente (SAR-Lag) y en los errores (SEM).
Incorporar rezagos espaciales de covariables (SLX) para capturar efectos de spillover.
Modelar la heterogeneidad espacial mediante regímenes espaciales.
Requisitos previos: 07_MatrizCorrelacion — Índice de Moran; 04_GLMPhyton — regresión lineal con statsmodels.
La regresión nos proporciona un caso perfecto para examinar cómo la estructura espacial puede ayudarnos a comprender y analizar nuestros datos. Por lo general, la estructura espacial ayuda a los modelos de dos maneras. La primera (y más clara) manera en que el espacio puede tener un impacto en nuestros datos es cuando el proceso que genera los datos es explícitamente espacial. Por ejemplo el caso del precio de las viviendas. A menudo sucede que las personas pagan un precio alto por su casa para vivir en un mejor distrito escolar para la misma calidad de casa. Alternativamente, las casas más cercanas a contaminantes acústicos o químicos como plantas de tratamiento de aguas residuales, instalaciones de reciclaje o carreteras anchas, pueden ser más baratas. La segunda manera en que la estructura espacial puede ayudarnos a entender nuestros datos es el ejemplo de la incidencia de asma. Los lugares a los que las personas tienden a viajar a lo largo del día, como sus lugares de trabajo o recreación, pueden tener más impacto en su salud que los sitios de sus viviendas. En este caso, puede ser necesario utilizar datos de otros sitios para predecir la incidencia de asma en un sitio dado. Independientemente del caso específico en juego, aquí, la geografía es una característica: nos ayuda directamente a hacer predicciones sobre resultados porque esos resultados provienen de procesos geográficos.
A menudo, en el análisis de métodos predictivos y clasificadores, estamos interesados en analizar lo que fallamos. Esto es común en econometría; un analista puede estar preocupado de que el modelo sistemáticamente predice mal algunos tipos de observaciones. Si sabemos que nuestro modelo rutinariamente se desempeña mal en un conjunto conocido de observaciones o tipo de entrada, podríamos hacer un mejor modelo si podemos tener en cuenta esto. Entre otros tipos de diagnósticos de errores, la geografía nos proporciona un incrustación excepcionalmente útil para evaluar la estructura en nuestros errores. Mapear el error de clasificación/predicción puede ayudar a mostrar si hay grupos de errores en nuestros datos. Si sabemos que los errores tienden a ser mayores en algunas áreas que en otras áreas (o si el error es “contagioso” entre observaciones), entonces podríamos aprovechar esta estructura para hacer mejores predicciones.
La estructura espacial en nuestros errores puede surgir de cuando la geografía debería ser de alguna manera un atributo, pero no estamos seguros exactamente de cómo incluirla en nuestro modelo. También pueden surgir porque hay alguna otra característica cuya omisión causa los patrones espaciales en el error que vemos; si esta característica adicional se incluyera, la estructura desaparecería. O podría surgir de las complejas interacciones e interdependencias entre las características que hemos elegido usar como predictores, lo que resulta en una estructura intrínseca en la mala predicción. La mayoría de los predictores que usamos en modelos de procesos sociales contienen información espacial incorporada: patrones intrínsecos a la característica que obtenemos de forma gratuita en el modelo. Si lo pretendemos o no, usar un predictor con patrón espacial en un modelo puede resultar en errores con patrón espacial; usar más de uno puede amplificar este efecto. Por lo tanto, independientemente de si el verdadero proceso es explícitamente geográfico, información adicional sobre las relaciones espaciales entre nuestras observaciones o más información sobre sitios cercanos puede hacer que nuestras predicciones sean mejores.
Los Datos: AirBnB en San Diego#
Para aprender un poco más sobre cómo funciona la regresión, examinaremos información sobre AirBnB en San Diego, CA. Este conjunto de datos contiene características intrínsecas de la casa, tanto continuas (número de camas como en beds) como categóricas (tipo de alquiler o, en el argot de AirBnb, grupo de propiedades como en las series de variables binarias de pg_X), pero también variables que se refieren explícitamente a la ubicación y configuración espacial del conjunto de datos (por ejemplo, distancia al Parque Balboa, d2balboa o identificación de vecindario, neighbourhood_cleansed).
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from pysal.model import spreg
from pysal.lib import weights
from pysal.explore import esda
from scipy import stats
import statsmodels.formula.api as sm
import numpy
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import seaborn as sbn
db = gpd.read_file('https://geographicdata.science/book/_downloads/dcd429d1761a2d0efdbc4532e141ba14/regression_db.geojson')
db.info()
<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 6110 entries, 0 to 6109
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 accommodates 6110 non-null int64
1 bathrooms 6110 non-null float64
2 bedrooms 6110 non-null float64
3 beds 6110 non-null float64
4 neighborhood 6110 non-null object
5 pool 6110 non-null int64
6 d2balboa 6110 non-null float64
7 coastal 6110 non-null int64
8 price 6110 non-null float64
9 log_price 6110 non-null float64
10 id 6110 non-null int64
11 pg_Apartment 6110 non-null int64
12 pg_Condominium 6110 non-null int64
13 pg_House 6110 non-null int64
14 pg_Other 6110 non-null int64
15 pg_Townhouse 6110 non-null int64
16 rt_Entire_home/apt 6110 non-null int64
17 rt_Private_room 6110 non-null int64
18 rt_Shared_room 6110 non-null int64
19 geometry 6110 non-null geometry
dtypes: float64(6), geometry(1), int64(12), object(1)
memory usage: 954.8+ KB
db.plot();
<Axes: >
db.head(2)
| accommodates | bathrooms | bedrooms | beds | neighborhood | pool | d2balboa | coastal | price | log_price | id | pg_Apartment | pg_Condominium | pg_House | pg_Other | pg_Townhouse | rt_Entire_home/apt | rt_Private_room | rt_Shared_room | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5 | 2.0 | 2.0 | 2.0 | North Hills | 0 | 2.972077 | 0 | 425.0 | 6.052089 | 6 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | POINT (-117.12971 32.75399) |
| 1 | 6 | 1.0 | 2.0 | 4.0 | Mission Bay | 0 | 11.501385 | 1 | 205.0 | 5.323010 | 5570 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | POINT (-117.25253 32.78421) |
Estas son las variables explicativas que utilizaremos a lo largo de este ejemplo.
variable_names = ['accommodates', 'bathrooms', 'bedrooms', 'beds', 'rt_Private_room', 'rt_Shared_room', 'pg_Condominium', 'pg_House', 'pg_Other', 'pg_Townhouse']
Regresión no espacial#
Antes de discutir cómo incluir explícitamente el espacio en el marco de regresión lineal, veamos cómo se puede llevar a cabo la regresión estandar (Gaussiana) en Python y cómo se pueden comenzar a interpretar los resultados. La idea principal de la regresión lineal es explicar la variación en una variable (dependiente) dada como una función lineal de una colección de otras variables (explicativas). Por ejemplo, en nuestro caso, podemos querer expresar/explicar el precio de una casa como una función de si es nueva y el grado de privacidad del área donde se encuentra. A nivel individual, podemos expresar esto como:
donde \(P_i\) es el precio de AirBnb de la casa \(i\), y \(X\) es un conjunto de covariables que usamos para explicar tal precio. \(\beta\) es un vector de parámetros que nos dan información sobre de qué manera y en qué medida cada variable está relacionada con el precio, y \(\alpha\), el término constante o también conocido como intercepto, es el precio promedio de la casa cuando todas las otras variables son cero. El término \(\epsilon_i\) se refiere comúnmente como “error” y captura elementos que influyen en el precio de una casa pero que no están incluidos en \(X\). También podemos expresar esta relación en forma de matriz, excluyendo subíndices para \(i\), lo que produce:
La regresión se puede pensar que es una extensión multivariada de las correlaciones bivariadas. Esto significa que, en lugar de mirar la relación entre dos variables (como en una correlación bivariada), la regresión permite ver cómo una variable depende de varias variables explicativas al mismo tiempo. De hecho, una forma de interpretar los coeficientes \(\beta_k\) en la ecuación anterior es como el grado de correlación entre la variable explicativa \(k\) y la variable dependiente, manteniendo constantes todas las demás variables explicativas. Cuando se calculan correlaciones solamente bivariadas, el coeficiente de una variable está captando la correlación entre las variables, pero también está asumiendo en ella la variación asociada con otras variables correlacionadas, también llamadas factores de confusión. La regresión nos permite aislar el efecto distinto que tiene una sola variable sobre la dependiente, una vez que controlamos por esas otras variables. Cuando hablamos de análisis bivariados, nos referimos a probabilidades marginales, es decir, cómo una variable se relaciona con la otra sin tener en cuenta el efecto de otras variables. En cambio, los modelos multivariados, como la regresión, nos dan probabilidades condicionales, es decir, cómo cambia una variable dependiente cuando controlamos por el efecto de otras variables.
En términos prácticos, las regresiones lineales en Python son bastante sencillas y fáciles de trabajar. También hay varios paquetes que las ejecutarán (por ejemplo, statsmodels, scikit-learn, PySAL). En el contexto de este libro, tiene sentido comenzar con PySAL, ya que es la única biblioteca que nos permitirá pasar a modelos econométricos explícitamente espaciales. Para ajustar el modelo especificado en la ecuación anterior con \(X\) como la lista definida, solo necesitamos la siguiente línea de código:
m1 = spreg.OLS(db[['log_price']].values, db[variable_names].values, name_y='log_price', name_x=variable_names)
Utilizamos el comando OLS, parte del subpaquete spreg, y especificamos la variable dependiente (el logaritmo del precio, para poder interpretar los resultados en términos de cambio porcentual) y las variables explicativas. Ten en cuenta que ambos objetos deben ser matrices, por lo que los extraemos del objeto pandas.DataFrame usando .values.
Para inspeccionar los resultados del modelo, podemos llamar a summary:
print(m1.summary)
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set : unknown
Weights matrix : None
Dependent Variable : log_price Number of Observations: 6110
Mean dependent var : 4.9958 Number of Variables : 11
S.D. dependent var : 0.8072 Degrees of Freedom : 6099
R-squared : 0.6683
Adjusted R-squared : 0.6678
Sum squared residual: 1320.15 F-statistic : 1229.0564
Sigma-square : 0.216 Prob(F-statistic) : 0
S.E. of regression : 0.465 Log likelihood : -3988.895
Sigma-square ML : 0.216 Akaike info criterion : 7999.790
S.E of regression ML: 0.4648 Schwarz criterion : 8073.685
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 4.38838 0.01611 272.32178 0.00000
accommodates 0.08345 0.00508 16.43363 0.00000
bathrooms 0.19238 0.01097 17.54198 0.00000
bedrooms 0.15252 0.01113 13.70092 0.00000
beds -0.04172 0.00694 -6.01344 0.00000
rt_Private_room -0.55069 0.01590 -34.62448 0.00000
rt_Shared_room -1.23831 0.03843 -32.21990 0.00000
pg_Condominium 0.14363 0.02215 6.48465 0.00000
pg_House -0.01049 0.01453 -0.72184 0.47042
pg_Other 0.14115 0.02280 6.19056 0.00000
pg_Townhouse -0.04167 0.03428 -1.21573 0.22413
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 11.964
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 2671.611 0.0000
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 10 322.532 0.0000
Koenker-Bassett test 10 135.581 0.0000
================================ END OF REPORT =====================================
Este mismo modelo se puede correr utilizando la función ols de statsmodels de la siguiente manera:
m0=sm.ols("log_price ~ accommodates + bathrooms + bedrooms + beds + rt_Private_room + rt_Shared_room + pg_Condominium + pg_House + pg_Other + pg_Townhouse", data=db).fit()
print(m0.summary())
OLS Regression Results
==============================================================================
Dep. Variable: log_price R-squared: 0.668
Model: OLS Adj. R-squared: 0.668
Method: Least Squares F-statistic: 1229.
Date: Fri, 11 Oct 2024 Prob (F-statistic): 0.00
Time: 17:43:14 Log-Likelihood: -3988.9
No. Observations: 6110 AIC: 8000.
Df Residuals: 6099 BIC: 8074.
Df Model: 10
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept 4.3884 0.016 272.322 0.000 4.357 4.420
accommodates 0.0835 0.005 16.434 0.000 0.073 0.093
bathrooms 0.1924 0.011 17.542 0.000 0.171 0.214
bedrooms 0.1525 0.011 13.701 0.000 0.131 0.174
beds -0.0417 0.007 -6.013 0.000 -0.055 -0.028
rt_Private_room -0.5507 0.016 -34.624 0.000 -0.582 -0.520
rt_Shared_room -1.2383 0.038 -32.220 0.000 -1.314 -1.163
pg_Condominium 0.1436 0.022 6.485 0.000 0.100 0.187
pg_House -0.0105 0.015 -0.722 0.470 -0.039 0.018
pg_Other 0.1412 0.023 6.191 0.000 0.096 0.186
pg_Townhouse -0.0417 0.034 -1.216 0.224 -0.109 0.026
==============================================================================
Omnibus: 964.842 Durbin-Watson: 1.836
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2671.611
Skew: 0.850 Prob(JB): 0.00
Kurtosis: 5.758 Cond. No. 41.5
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Los Coeficientes nos dan las estimaciones para \(\beta_k\) en nuestro modelo. En otras palabras, estos números expresan la relación entre cada variable explicativa y la variable dependiente, una vez que se ha tenido en cuenta el efecto de los factores de confusión. Sin embargo, ten en cuenta que la regresión no es magia; solo estamos descontando el efecto de los factores de confusión que incluimos en el modelo, no de todos los factores potencialmente confusos.
Los resultados son en su mayoría como se esperaba: las casas tienden a ser significativamente más caras si acomodan a más personas (accommodates), si tienen más baños y dormitorios y si son un condominio o parte de la categoría “otro” tipo de vivienda. Por otro lado, dada una cantidad de habitaciones, las casas con más camas (es decir, listados más “abarrotados”) tienden a ser más baratas, como es el caso de las propiedades donde no se alquila toda la casa sino solo una habitación (rt_Private_room) o incluso se comparte (rt_Shared_room). Por supuesto, podrías dudar conceptualmente de la suposición de que es posible cambiar arbitrariamente el número de camas dentro de un Airbnb sin eventualmente cambiar el número de personas que acomoda, pero los métodos para abordar estas preocupaciones usando efectos de interacción no se discutirán aquí.
En general, nuestro modelo se desempeña bien, siendo capaz de predecir ligeramente más del 66% (\(R^2=0.66\)) de la variación en el precio medio por noche usando las covariables que hemos discutido anteriormente. Pero, nuestro modelo podría mostrar cierto agrupamiento en los errores. Para investigar esto, podemos hacer algunas cosas. Un concepto simple podría ser observar la correlación entre el error en la predicción de un airbnb y el error en la predicción de su vecino más cercano. Para examinar esto, primero podríamos querer dividir nuestros datos por regiones y ver si tenemos alguna estructura espacial en nuestros residuos. Una teoría razonable podría ser que nuestro modelo no incluye ninguna información sobre playas, un aspecto crítico de por qué las personas viven y vacacionan en San Diego. Por lo tanto, podríamos querer ver si nuestros errores son mayores o menores dependiendo de si un airbnb está en un vecindario “de playa”, un vecindario cerca del océano:
A continuación se obtienen los residuos para el modelo cuando la variable is_coastal es igual a True, lo cual significa que la casa está localizada sobre la costa.
is_coastal = db.coastal.astype(bool)
coastal = m1.u[is_coastal]
not_coastal = m1.u[~is_coastal]
plt.hist(coastal, density=True, label='Coastal')
plt.hist(not_coastal, histtype='step', density=True, linewidth=4, label='Not Coastal')
plt.vlines(0,0,1, linestyle=":", color='k', linewidth=4)
plt.legend()
plt.show()
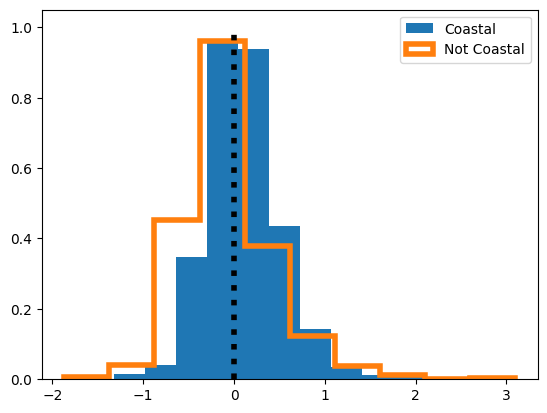
Aunque parece que los vecindarios en la costa tienen errores promedio solo ligeramente más altos (y tienen menor varianza en sus errores de predicción), las dos distribuciones son significativamente distintas entre sí cuando se comparan usando una prueba \(t\) clásica:
stats.ttest_ind(coastal, not_coastal)
# permutations=9999 not yet available in scipy
TtestResult(statistic=array([13.98193858]), pvalue=array([9.442438e-44]), df=array([6108.]))
Sin embargo, existen pruebas más sofisticadas (y más difíciles de engañar) que pueden ser aplicables para estos datos, como el Índice de Moran y el Multiplicador de Lagrange. Además, podría ser el caso de que algunos vecindarios sean más deseables que otros debido a preferencias latentes o estrategias de marketing no modeladas. Por ejemplo, a pesar de su ubicación cerca del mar, vivir cerca de Camp Pendleton, una base de Marines en el norte de la ciudad, podría incurrir en algunas penalizaciones significativas en la deseabilidad del área debido al ruido y la contaminación. Para determinar si este es el caso, podríamos estar interesados en la distribución completa de los residuos del modelo dentro de cada vecindario.
Para hacer esto más claro, primero ordenaremos los datos por la mediana residual en ese vecindario, y luego haremos un diagrama de caja, que muestra la distribución de los residuos en cada vecindario:
db.head(2)
| accommodates | bathrooms | bedrooms | beds | neighborhood | pool | d2balboa | coastal | price | log_price | id | pg_Apartment | pg_Condominium | pg_House | pg_Other | pg_Townhouse | rt_Entire_home/apt | rt_Private_room | rt_Shared_room | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5 | 2.0 | 2.0 | 2.0 | North Hills | 0 | 2.972077 | 0 | 425.0 | 6.052089 | 6 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | POINT (-117.12971 32.75399) |
| 1 | 6 | 1.0 | 2.0 | 4.0 | Mission Bay | 0 | 11.501385 | 1 | 205.0 | 5.323010 | 5570 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | POINT (-117.25253 32.78421) |
db['residual'] = m1.u
medians = db.groupby("neighborhood").residual.median().to_frame('hood_residual')
f = plt.figure(figsize=(15,3))
ax = plt.gca()
sbn.boxplot(x='neighborhood', y='residual', ax = ax,
data=db.merge(medians, how='left',left_on='neighborhood',right_index=True).sort_values('hood_residual'), palette='bwr', dodge=False)
f.autofmt_xdate()
plt.show()
C:\Users\edier\AppData\Local\Temp\ipykernel_13996\1987411078.py:6: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sbn.boxplot(x='neighborhood', y='residual', ax = ax,
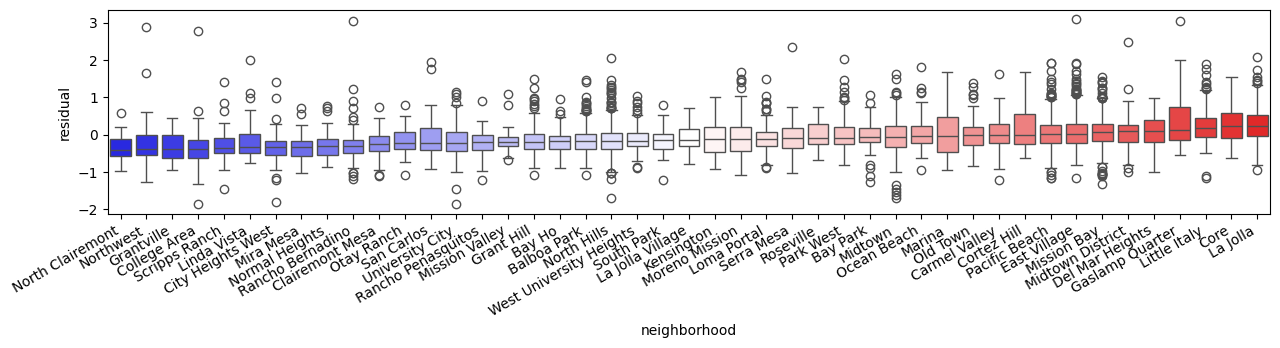
Ningún vecindario está completamente aislado de los demás, pero algunos parecen ser más destacados que otros, como las conocidas áreas turísticas del centro de la ciudad, como Gaslamp Quarter, Little Italy o The Core. Por lo tanto, puede haber un efecto distintivo de la moda del vecindario que importa en este modelo.
Observando que muchos de los vecindarios más sobre y subestimados están cerca unos de otros en la ciudad, también puede ser el caso de que haya algún tipo de contagio o derrame espacial en el precio del alquiler nocturno. Esto a menudo es evidente cuando las personas buscan fijar el precio de sus listados de Airbnb para competir con listados similares cercanos. Dado que nuestro modelo no es consciente de este comportamiento, es posible que sus errores tiendan a agruparse. Una forma excepcionalmente simple de investigar esta estructura es examinando la relación entre los residuos de una observación y los residuos circundantes.
Para hacer esto, utilizaremos pesos espaciales para representar las relaciones geográficas entre las observaciones. Para este ejemplo, comenzaremos con una matriz \(KNN\) donde \(k=5\), lo que significa que nos enfocaremos solo en los enlaces de cada Airbnb con sus otros 5 vecinos más cercanos.
knn = weights.KNN.from_dataframe(db, k=5)
C:\Users\edier\miniconda3\Lib\site-packages\libpysal\weights\weights.py:224: UserWarning: The weights matrix is not fully connected:
There are 11 disconnected components.
warnings.warn(message)
Esto significa que, cuando calculamos el lag espacial de ese peso knn y el residuo, obtenemos el residuo del listado de Airbnb más cercano a cada observación.
lag_residual = weights.spatial_lag.lag_spatial(knn, m1.u) # se obtiene la columna spatial_lag de la matris denominada Weights y se le calcula el espacial lag con la matriz de KNN
ax = sbn.regplot(x=m1.u.flatten(), y=lag_residual.flatten(),line_kws=dict(color='orangered'),ci=None)
ax.set_xlabel('Model Residuals - $u$')
ax.set_ylabel('Spatial Lag of Model Residuals - $W u$');
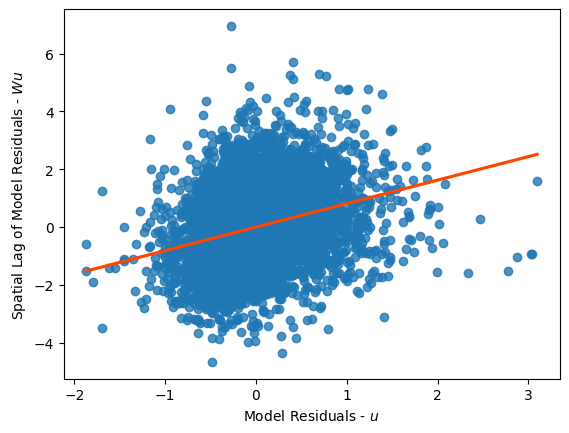
En este gráfico, vemos que nuestros errores de predicción tienden a agruparse. Arriba, mostramos la relación entre nuestro error de predicción en cada sitio y el error de predicción en el sitio más cercano a él. Aquí, estamos utilizando este sitio más cercano para representar el entorno de ese Airbnb. Esto significa que, cuando el modelo tiende a sobreestimar el precio logarítmico nocturno de un determinado Airbnb, es más probable que los sitios alrededor de ese Airbnb también sean sobreestimados.
Una propiedad interesante de esta relación es que tiende a estabilizarse a medida que aumenta el número de vecinos más cercanos utilizados para construir el entorno de cada Airbnb.
Dado este comportamiento, veamos el número estable de vecinos \(k=20\). Examinando la relación entre este promedio estable del entorno y el Airbnb focal, incluso podemos encontrar clusters en el error de nuestro modelo. Recordando las estadísticas de Índice de Moran local, podemos identificar ciertas áreas donde nuestras predicciones del precio nocturno (logarítmico) de Airbnb tienden a ser significativamente incorrectas:
knn.reweight(k=20, inplace=True)
outliers = esda.moran.Moran_Local(m1.u, knn, permutations=9999)
error_clusters = (outliers.q % 2 == 1) # only the cluster cores
error_clusters &= (outliers.p_sim <= .001) # filtering out non-significant clusters
db.assign(error_clusters = error_clusters, local_I = outliers.Is).query("error_clusters").sort_values('local_I').plot('local_I', cmap='bwr', marker='.');
C:\Users\edier\miniconda3\Lib\site-packages\libpysal\weights\weights.py:224: UserWarning: The weights matrix is not fully connected:
There are 3 disconnected components.
warnings.warn(message)
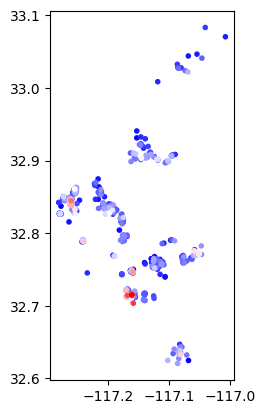
Por lo tanto, estas áreas tienden a ser lugares donde nuestro modelo subestima significativamente el precio nocturno de Airbnb tanto para esa observación específica como para las observaciones en sus alrededores inmediatos. Esto es crítico porque, si podemos identificar cómo están estructuradas estas áreas y tienen una geografía consistente que podemos modelar, entonces podríamos mejorar nuestras predicciones, o al menos no predecir sistemáticamente mal los precios en algunas áreas mientras que predecimos correctamente los precios en otras áreas.
Dado que las subestimaciones y sobreestimaciones significativas parecen agruparse de manera altamente estructurada, podríamos usar un modelo mejor para corregir la geografía de los errores de nuestro modelo.
Incorporar variables espaciales#
Utilizar información geográfica para “construir” nuevos datos es un enfoque común para incorporar información espacial en el análisis geográfico. A menudo, esto refleja el hecho de que los procesos no son iguales en todas partes en el mapa de análisis, o que la información geográfica puede ser útil para predecir nuestro resultado de interés. En esta sección, presentaremos brevemente cómo usar características espaciales, o variables \(X\) que se construyen a partir de relaciones geográficas, en un modelo lineal estándar.
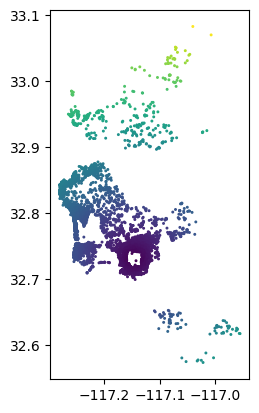
Para empezar, una variable relevante impulsada por la proximidad que podría influir en nuestro modelo se basa en la proximidad de las listas al Parque Balboa. Un destino turístico común, el Parque Balboa es un centro recreativo central para la ciudad de San Diego, que contiene muchos museos y el zoológico de San Diego. Por lo tanto, podría ser el caso de que las personas que buscan Airbnbs en San Diego estén dispuestas a pagar más para vivir más cerca del parque. Si esto fuera cierto y lo omitiéramos de nuestro modelo, de hecho podríamos ver un patrón espacial significativo causado por este efecto de decaimiento de la distancia.
Por lo tanto, a esto a veces se le llama una covariable omitida con patrón espacial: información geográfica que nuestro modelo necesita para hacer buenas predicciones y que hemos dejado fuera de nuestro modelo. Por lo tanto, construyamos un nuevo modelo que contenga esta covariable de distancia al Parque Balboa. Sin embargo, primero es útil visualizar la estructura de esta covariable de distancia en sí misma:
db.plot('d2balboa', marker='.', s=5)
<Axes: >
base_names = variable_names
balboa_names = variable_names + ['d2balboa']
m2 = spreg.OLS(db[['log_price']].values, db[balboa_names].values,name_y = 'log_price', name_x = balboa_names)
Desafortunadamente, al inspeccionar los diagnósticos de regresión y la salida, se observa que esta covariable no es tan útil como podríamos anticipar. No es estadísticamente significativa a niveles de significancia convencionales, y el ajuste del modelo no cambia sustancialmente.
print(m2.summary)
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set : unknown
Weights matrix : None
Dependent Variable : log_price Number of Observations: 6110
Mean dependent var : 4.9958 Number of Variables : 12
S.D. dependent var : 0.8072 Degrees of Freedom : 6098
R-squared : 0.6685
Adjusted R-squared : 0.6679
Sum squared residual: 1319.52 F-statistic : 1117.9338
Sigma-square : 0.216 Prob(F-statistic) : 0
S.E. of regression : 0.465 Log likelihood : -3987.446
Sigma-square ML : 0.216 Akaike info criterion : 7998.892
S.E of regression ML: 0.4647 Schwarz criterion : 8079.504
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 4.37962 0.01692 258.91622 0.00000
accommodates 0.08364 0.00508 16.46982 0.00000
bathrooms 0.19079 0.01100 17.33717 0.00000
bedrooms 0.15075 0.01118 13.48429 0.00000
beds -0.04148 0.00694 -5.97748 0.00000
rt_Private_room -0.55300 0.01596 -34.64902 0.00000
rt_Shared_room -1.23552 0.03846 -32.12328 0.00000
pg_Condominium 0.14046 0.02223 6.31983 0.00000
pg_House -0.01330 0.01462 -0.90966 0.36304
pg_Other 0.14118 0.02280 6.19244 0.00000
pg_Townhouse -0.04578 0.03436 -1.33264 0.18270
d2balboa 0.00165 0.00097 1.70086 0.08902
------------------------------------------------------------------------------------
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 12.745
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 2710.322 0.0000
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 11 317.519 0.0000
Koenker-Bassett test 11 132.860 0.0000
================================ END OF REPORT =====================================
lag_residual = weights.spatial_lag.lag_spatial(knn, m2.u)
sbn.regplot(x=m2.u.flatten(), y=lag_residual.flatten(),line_kws=dict(color='orangered'),ci=None);
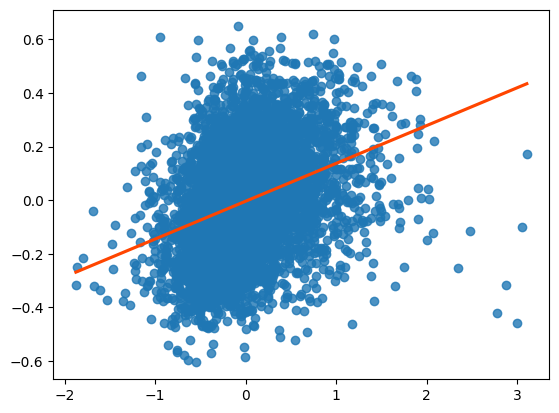
Finalmente, la variable de distancia al Parque Balboa no se ajusta a nuestra teoría sobre cómo debería afectar el precio de un Airbnb la distancia a un lugar de interés; el estimado del coeficiente es positivo, lo que significa que las personas están pagando más para estar más alejadas del parque.
Dependencia y Heterogeneidad espacial#
La regresión espacial se trata de introducir explícitamente el espacio o el contexto geográfico en el marco estadístico de una regresión. Conceptualmente, queremos introducir el espacio en nuestro modelo siempre que pensemos que juega un papel importante en el proceso en el que estamos interesados, o cuando el espacio puede actuar como un proxy razonable para otros factores que no podemos pero deberíamos incluir en nuestro modelo. Como ejemplo de lo primero, podemos imaginar cómo las casas en el corredor del mar probablemente sean más caras que las de la segunda fila, dadas sus mejores vistas.
Para ilustrar lo último, podemos pensar en cómo el carácter de un vecindario es importante para determinar el precio de una casa; sin embargo, es muy difícil identificar y cuantificar el “carácter” en sí mismo, aunque podría ser más fácil abordar su variación espacial, de ahí un caso de espacio como proxy.
La regresión espacial es un gran campo de desarrollo en las literaturas de econometría y estadística. En esta breve introducción, consideraremos dos procesos relacionados pero muy diferentes que dan lugar a efectos espaciales: Heterogeneidad Espacial (SH) y Dependencia Espacial (SD).
Para atender esta problemática es necesario inicialmente comprender la estructura espacial de los datos. La estructura espacial se puede descomponer en dos componentes principales: la heterogeneidad espacial y la dependencia espacial (Anselin 1996, Rey et al. 2023). La heterogeneidad espacial se refiere a la variación en las propiedades de los datos en diferentes áreas del espacio, lo que implica que las relaciones entre las variables no necesariamente sean homogéneas en toda la región de estudio (Rey et al. 2023). La dependencia espacial, por otro lado, se refiere a la tendencia de valores similares a agruparse espacialmente (Anselin 1988). Esto implica que el valor de una variable en un punto del espacio está correlacionado con los valores de la misma variable en puntos cercanos, un fenómeno también conocido como autocorrelación. Esta dependencia puede originarse debido a procesos naturales que presentan continuidad espacial, como la geología y la topografía, o debido a factores ambientales como la vegetación y el clima (Lombardo et al. 2020), que tienden a presentar patrones espaciales similares en áreas cercanas.
Cuando la heterogeneidad y la dependencia espacial no se incorporan adecuadamente en los modelos, la estructura espacial queda remanente en los residuales, lo cual se traduce en una falta de ajuste adecuada del modelo (Anselin 2022, Cressie 2015). Este remanente espacial en los residuos es una violación de las suposiciones de independencia que subyacen a los modelos clásicos, ya que los modelos clásicos suelen asumir que las observaciones son independientes entre sí (sin dependencia espacial) y que la relación entre las variables es constante en toda la región de estudio (sin heterogeneidad espacial) (Lesage 2011, Banerjee 2008). Esto afecta la validez de las inferencias estadísticas y resulta en modelos con predicciones sesgadas.

Actividades#
Diagnóstico espacial de OLS: Ajusta un modelo OLS para explicar
lands_rec(transformada con log(x+1)) en función de las tres covariables estandarizadas del dataset de cuencas. Calcula el Moran I de los residuos usando una matriz Queen. ¿Los residuos muestran autocorrelación espacial significativa? ¿Qué implicaciones tiene esto sobre los supuestos del OLS?Selección de modelo espacial: Usando los tests de multiplicadores de Lagrange (LM-lag y LM-error) disponibles en
pysal, determina si el problema de los residuos en el ejercicio 1 se corrige mejor con un modelo SAR-Lag o un modelo SEM. Justifica tu elección.Regresión con rezagos espaciales de X: Ajusta un modelo SLX (Spatially Lagged X) añadiendo el rezago espacial de cada covariable como variable adicional. Compara el R² ajustado y el AIC con el OLS del ejercicio 1. ¿Aportan los efectos de spillover información adicional?
Regímenes espaciales: Divide el dataset de cuencas en dos regímenes: subcuencas de la Cordillera Occidental (cuenca Atrato) y subcuencas de las Cordilleras Central y Oriental (cuencas Cauca y Magdalena). Ajusta un OLS con régimen espacial (coeficientes distintos por régimen). ¿Son estadísticamente distintos los coeficientes entre regímenes para la variable
slope_mean?
Recursos adicionales#
Documentación oficial#
Lecturas recomendadas#
Anselin, L. (1988). Spatial Econometrics: Methods and Models. Kluwer Academic Publishers.
LeSage, J. & Pace, R. K. (2009). Introduction to Spatial Econometrics. CRC Press.
Bivand, R. S., Pebesma, E., & Gómez-Rubio, V. (2013). Applied Spatial Data Analysis with R (2nd ed.). Springer.
Elhorst, J. P. (2014). Spatial Econometrics: From Cross-Sectional Data to Spatial Panels. Springer.