Créditos: El contenido de este cuaderno ha sido tomado de varias fuentes, pero especialmente de Wikipedia, pero especialmente de los cursos y libros publicados abierta y libremente por Dani Arribas-Bel - University of Liverpool & Sergio Rey - Center for Geospatial Sciences, University of California, Riverside. El compilador se disculpa por cualquier omisión involuntaria y estaría encantado de agregar un reconocimiento.
Patrón de puntos#
Los puntos son entidades espaciales que pueden entenderse de dos maneras fundamentalmente diferentes:
Por un lado, los puntos pueden considerarse como objetos fijos en el dominio del espacio, es decir, su ubicación se toma como dada (exógena). En esta interpretación, la ubicación de un punto observado se considera secundaria en comparación con el valor observado en el punto. Piensa en esto como medir el número de autos que atraviesan una intersección de carreteras; la ubicación es fija y los datos de interés provienen de la medición realizada en esa ubicación. El análisis de este tipo de datos puntuales es muy similar al de otros tipos de datos espaciales discretos, como polígonos y líneas.
Por otro lado, una observación que ocurre en un punto también puede verse como un sitio de medición de un proceso geográficamente continuo subyacente. En este caso, la medición teóricamente podría realizarse en cualquier lugar, pero solo se llevó a cabo en ciertos sitios. Piensa en esto como medir la longitud de las alas de los pájaros: la ubicación en la que se mide refleja el proceso geográfico subyacente del movimiento y forrajeo de los pájaros, y la longitud de sus alas puede reflejar un proceso ecológico subyacente que varía según el pájaro. Este enfoque implica que tanto la ubicación como la medición importan. Esta es la perspectiva que adoptaremos en este capítulo.
Cuando los puntos se ven como eventos que podrían ocurrir en varios lugares pero solo suceden en algunos, a una colección de tales eventos se le llama un patrón de puntos. En este caso, la ubicación de los puntos es uno de los aspectos clave de interés para el análisis. Un buen ejemplo de un patrón de puntos son las fotos georreferenciadas: técnicamente podrían tomarse en muchos lugares, pero generalmente encontramos que las fotos tienden a concentrarse solo en unos pocos de ellos. Los patrones de puntos pueden estar marcados, si se proporcionan más atributos junto con la ubicación, o no marcados, si solo se proporcionan las coordenadas de donde ocurrió el evento. Continuando con el ejemplo de las fotos, un patrón no marcado sería si solo se utiliza la ubicación donde se tomaron las fotos para el análisis, mientras que hablaríamos de un patrón de puntos marcado si se proporcionan otros atributos, como el tiempo, el modelo de cámara o una “puntuación de calidad de imagen” junto con la ubicación.
En Geoestadística o datos discretos cuando se está estudiando la calidad del suelo en una región agrícola, sabes de antemano cuáles son las ubicaciones donde realizarás las mediciones, o los polígonos (lotes) que analizarás. Aquí, el dominio es fijo porque las ubicaciones están predefinidas y están relacionadas con un espacio continuo o discretamente definido. Mietras que en patrones de puntos estás estudiando por ejemplo la distribución espacial de deslizamientos después de una tormenta. Los deslizamientos pueden ocurrir en cualquier parte de una región, y su ubicación no es fija, sino que depende de factores estocásticos como la lluvia y las condiciones del terreno. Aquí el dominio no es fijo porque los puntos (eventos) no son determinados de antemano, sino que ocurren según un proceso aleatorio.
Este concepto, aparentemente simple, puede ser dificil de entender y diferenciar de los análisis geoestadísticos o análisis areales. El siguiente ejemplo se encuentra en el libro de Schabenberger & Gotway (2005). Considera que estás vaciando arena de un balde sobre un escritorio, y llamemos \(Z(s)\) a la profundidad de la arena vertida en la ubicación s. El conjunto \(D\) representa todas las posibles ubicaciones en este experimento, es decir, toda la superficie del escritorio. Luego de medir la profundidad de la arena en algunos puntos del escritorio, se regresa la arena al balde y se vuelve a verter. Este proceso produce otra realización del proceso aleatorio {\(Z(s)\) : \(s\) \(∈\) \(D\) \(⊂\) \(R^2\)}. Ahora tenemos dos realizaciones de un proceso geoestadístico; la superficie (dominio) no ha cambiado entre el primer y el segundo vertido, a menos que alguien haya movido el escritorio. El objetivo del análisis estadístico con estos datos es extraer información sobre el atributo \(Z\), como por ejemplo, construir un mapa de elevación de la arena sobre el escritorio. El objetivo no es estudiar el escritorio, ya que el dominio es conocido y permanece invariable.
Ahora bien, ¿podemos imaginar un dominio aleatorio en este ejemplo? Es decir, un conjunto de puntos que cambia con cada realización del proceso aleatorio. Supongamos que \(Z(s)\) representa la profundidad de la arena en la ubicación \(s\), y aplicamos una transformación mediante un indicador de la siguiente forma:
I(s) = 1 si Z(s) > c I(s) = 0 en otro caso.
Si \(Z(s)\) es un dato geoestadístico, entonces el indicador \(I(s)\) también lo es. Este indicador toma el valor de 1 siempre que la profundidad de la arena exceda un umbral \(c\). Ahora, eliminamos todas las ubicaciones en \(D\) donde \(I(s) = 0\) y definimos el conjunto restante de puntos como \(D*\). A medida que repetimos el proceso de verter la arena, se obtiene una realización distinta del conjunto aleatorio \(D*\). Tanto el número de puntos del conjunto realizado como su configuración espacial ahora son el resultado de un proceso aleatorio. El atributo “observado” en cada punto de \(D*\) es más bien poco interesante, \(I(s) ≡ 1\), si \(s\) \(∈\) \(D*\). En este caso, el foco del análisis estadístico es el conjunto \(D*\) en sí mismo; es decir, estudiamos las propiedades del dominio aleatorio. Este análisis corresponde al campo del análisis de patrones puntuales. La colección de puntos \(I(s)\), \(s\) \(∈\) \(D*\), se conoce como un patrón de puntos.
Un ejemplo probablemente más sencillo es suponer que estás observando un bosque desde arriba, como si estuvieras viendo un mapa aéreo. Cada árbol en el bosque se puede representar por un punto en ese mapa. Estos puntos representan las posiciones de los árboles, y su disposición sobre el terreno es lo que llamamos un “patrón de puntos”. Dependiendo del tipo de bosque, la distribución de los árboles puede ser más o menos uniforme: en un bosque plantado, los árboles tienden a estar ordenados en filas y columnas (es un patrón regular), mientras que en un bosque natural, los árboles se distribuyen de manera aparentemente aleatoria (un patrón aleatorio). Ahora imagina que los árboles están creciendo de manera desigual. Quizás, algunos árboles crecen mejor en ciertas áreas del bosque donde hay más agua, o donde la luz del sol llega de manera más intensa. Al medir la altura de cada árbol, notarás que en algunos lugares del bosque los árboles son más altos y en otros lugares son más bajos. Esta variabilidad nos ayuda a entender la distribución espacial de algún atributo, en este caso, la altura de los árboles. Para analizar mejor estos patrones, podrías definir una regla, por ejemplo: “Considero solamente los árboles cuya altura sea mayor a 5 m.” Siguiendo esta regla, miras nuevamente el bosque y decides que sólo vas a marcar aquellos árboles que cumplen con esa condición (altura > 5 metros). Así, el conjunto de puntos (árboles) que seleccionas constituye un “nuevo patrón de puntos”. Este proceso de selección puede hacerse varias veces, con el resultado de que cada vez, dependiendo de factores como la cantidad de agua o nutrientes en el suelo, el patrón de árboles más altos (mayores a 5 m) puede cambiar. Los lugares donde quedan los árboles seleccionados van variando de un intento a otro, mostrando un patrón de puntos que cambia con cada realización. En este sentido, el patrón de puntos es aleatorio porque los lugares seleccionados son diferentes cada vez.
Este tipo de análisis se denomina análisis de patrones de puntos y se utiliza para estudiar la distribución de los elementos en el espacio. No nos interesa solamente dónde están los árboles, sino también cómo cambian sus posiciones o si existen agrupamientos en algunas áreas del bosque que puedan explicarse por factores ambientales. En la práctica, el análisis de patrones de puntos es muy útil en distintas áreas de investigación: por ejemplo, para estudiar la ubicación de terremotos a lo largo de una falla geológica, la distribución de especies animales en un parque, o incluso la aparición de casos de enfermedades en una ciudad. Este análisis nos permite entender si los eventos (como terremotos, árboles, o enfermedades) ocurren de forma completamente aleatoria o si hay alguna estructura o patrón detrás de su ocurrencia.
El análisis de patrones de puntos se ocupa de la visualización, descripción, caracterización estadística y modelado de patrones de puntos, tratando de comprender el proceso generador que da lugar y explica los datos observados. Las preguntas comunes en este campo incluyen:
¿Cómo se ve el patrón?
¿Cuál es la naturaleza de la distribución de los puntos?
¿Existe alguna estructura en la forma en que se disponen las ubicaciones en el espacio? Es decir, ¿los eventos están agrupados o están dispersos?
¿Por qué ocurren los eventos en esos lugares y no en otros?
Estas son las preguntas más comunes en el análisis de patrones de puntos.
En este punto, es útil recordar una distinción importante entre proceso y patrón. El primero se refiere al mecanismo subyacente que está en funcionamiento para generar el resultado que observamos. Debido a su naturaleza abstracta, no lo vemos directamente. Sin embargo, en muchos contextos, el foco principal del análisis es aprender sobre qué determina un fenómeno dado y cómo se combinan esos factores para generarlo. En este contexto, el “proceso” está asociado con el cómo. Por otro lado, el “patrón” se refiere al resultado de ese proceso. En algunos casos, es la única evidencia del proceso que podemos observar y, por lo tanto, el único insumo con el que contamos para reconstruirlo. Aunque observable directamente y, quizás, más fácil de abordar, el patrón es solo un reflejo del proceso. El verdadero desafío no es caracterizar el primero, sino usarlo para deducir el segundo.
En este capítulo, proporcionamos una introducción a los patrones de puntos a través de fotos georreferenciadas de Flickr en Tokio. Trataremos los fenómenos representados en los datos como eventos: las fotos podrían tomarse en cualquier lugar de Tokio, pero solo se capturan en ciertas ubicaciones. Ten en cuenta que esta comprensión de las fotos de Tokio no es inmutable: uno podría concebir casos en los que tiene sentido considerar esas ubicaciones como dadas y analizar sus propiedades ignorando su aspecto de “evento”. Sin embargo, en este contexto, nos centraremos en aquellas preguntas que se relacionan con la ubicación y la forma colectiva de las ubicaciones. El uso de estas herramientas nos permitirá transformar una larga lista de coordenadas XY ininteligibles en fenómenos tangibles con una estructura espacial característica, y responder preguntas sobre el centro, la dispersión y la agrupación de atracciones en Tokio para los usuarios de Flickr.
Objetivos de aprendizaje#
Al finalizar este notebook, el estudiante será capaz de:
Distinguir entre patrones de puntos marcados y no marcados, y entre proceso y patrón.
Aplicar técnicas de centrografía (centro medio, distancia estándar, elipse de desviación) para describir la distribución espacial.
Calcular e interpretar estimaciones de densidad de kernel (KDE) con distintos anchos de banda.
Implementar y leer las funciones de Ripley G y F para inferir la naturaleza del proceso (agrupado, aleatorio, regular).
Identificar clusters espaciales mediante el algoritmo DBSCAN con
scikit-learn.
Requisitos previos: 01_DatosEspaciales — GeoDataFrames; nociones de estadística descriptiva.
# Read remote file
import pandas as pd
db = pd.read_csv("https://geographicdata.science/book/_downloads/7fb86b605af15b3c9cbd9bfcbead23e9/tokyo_clean.csv")
La tabla contiene la siguiente información sobre la muestra de 10,000 fotografías: el ID del usuario que tomó la foto; la ubicación expresada en columnas de latitud y longitud; una versión transformada de esas coordenadas expresadas en Pseudo Mercator; la marca de tiempo cuando se tomó la foto; y la URL donde se almacena en línea la fotografía a la que se refiere.
db.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 10000 non-null object
1 longitude 10000 non-null float64
2 latitude 10000 non-null float64
3 date_taken 10000 non-null object
4 photo/video_page_url 10000 non-null object
5 x 10000 non-null float64
6 y 10000 non-null float64
dtypes: float64(4), object(3)
memory usage: 547.0+ KB
Visualización#
El primer paso para tener una idea de cómo se ve la dimensión espacial de este conjunto de datos es graficarlo. En su nivel más básico, podemos generar un diagrama de dispersión con seaborn:
# Generate scatter plot
import seaborn as sbn
sbn.jointplot(x='longitude', y='latitude', data=db, s=0.5);
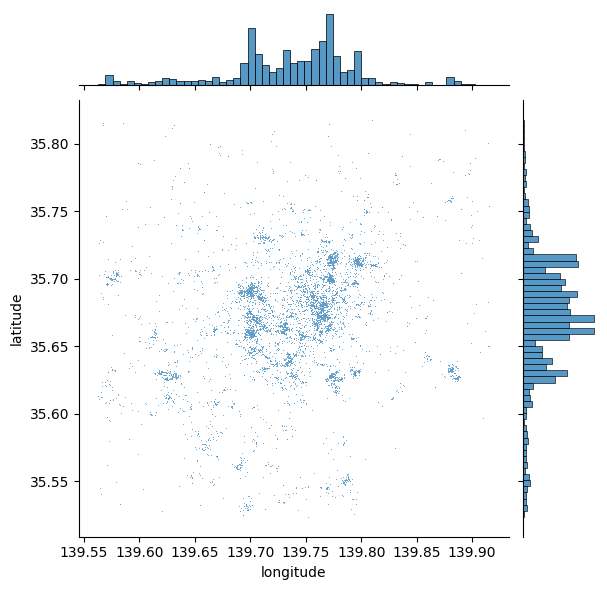
Este es un buen comienzo: podemos ver que los puntos tienden a concentrarse en el centro del área cubierta de una manera que (aparentemente) no es aleatoria. Además, dentro del patrón general, también parece haber más grupos localizados. Sin embargo, el gráfico anterior tiene dos inconvenientes clave: uno, carece de contexto geográfico; y dos, hay áreas donde la densidad de puntos es tan grande que es difícil distinguir algo más allá de una mancha azul.
El enfoque presentado anteriormente funciona hasta un cierto número de puntos a graficar; ajustar la transparencia y el tamaño de los puntos solo nos lleva hasta cierto punto, y en algún momento, necesitamos cambiar el enfoque. Después de aprender sobre la visualización de datos en mallas (polígonos), una opción es “convertir” puntos en polígonos y aplicar técnicas como el mapeo coroplético para visualizar su distribución espacial. Para hacerlo, superpondremos una capa de polígonos sobre el patrón de puntos, asignando los puntos a los polígonos al asignar a cada punto el polígono en el que se encuentra, y crearemos un coropleta de los conteos por polígono.
Este enfoque es intuitivo pero, por supuesto, plantea la siguiente pregunta: ¿qué polígonos usamos para agregar los puntos? Idealmente, queremos una delimitación que coincida lo más posible con el proceso generador de puntos y que divida el espacio en áreas con una intensidad interna de puntos similar. Sin embargo, ese no suele ser el caso, sobre todo porque una de las principales razones por las que normalmente queremos visualizar el patrón de puntos es aprender sobre dicho proceso generador, por lo que, típicamente, no sabríamos de antemano si un conjunto de polígonos coincide con este. Si no podemos contar con el conjunto ideal de polígonos desde el principio, podemos adoptar dos enfoques más realistas: usar un conjunto de áreas irregulares preexistentes o crear un conjunto artificial de polígonos regulares. Exploremos ambos.
Mallas irregulares#
Para ejemplificar este enfoque, utilizaremos las áreas administrativas que hemos cargado anteriormente. Vamos a agregarlas a la figura anterior para obtener un mejor contexto.
import geopandas as gpd
areas = gpd.read_file("https://darribas.org/gds_course/content/data/tokyo_admin_boundaries.geojson")
areas.plot();
areas.crs
<Geographic 2D CRS: EPSG:4326>
Name: WGS 84
Axis Info [ellipsoidal]:
- Lat[north]: Geodetic latitude (degree)
- Lon[east]: Geodetic longitude (degree)
Area of Use:
- undefined
Datum: World Geodetic System 1984
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
# Plot photographs with smaller, more translucent dots
ax = db.plot.scatter("longitude","latitude",s=0.25,c="xkcd:bright yellow",alpha=0.5,figsize=(9, 9))
# Add administrative boundaries
areas.plot(ax=ax,facecolor="none",edgecolor="xkcd:pale lavender")
# remove axis
ax.set_axis_off()
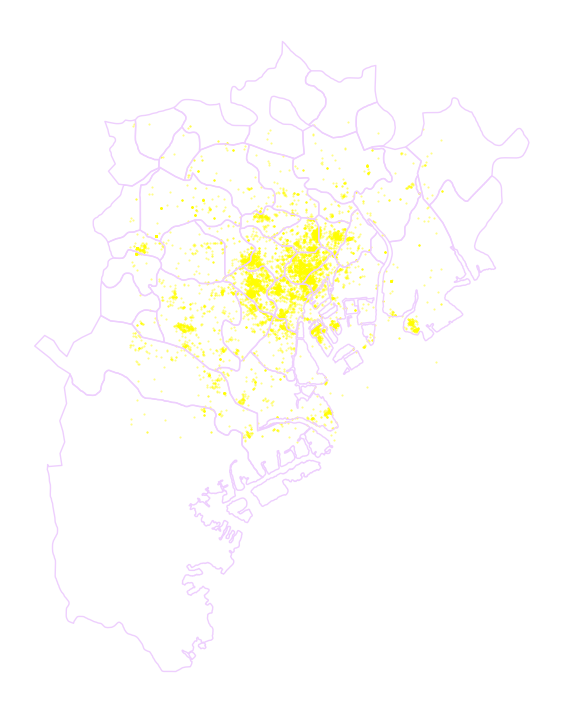
Ahora necesitamos saber cuántas fotografías contiene cada área. Nuestra tabla de fotografías ya contiene el ID del área, por lo que todo lo que necesitamos hacer aquí es contar por área y adjuntar el conteo a la tabla areas. Para esto, podemos utilizar el operador groupby, que toma todas las fotos de la tabla y las “agrupa” “por” su ID administrativo. Una vez agrupadas, aplicamos el método size, que cuenta cuántos elementos tiene cada grupo y devuelve una columna indexada por el código LSOA con todos los conteos como valores. Finalmente, asignamos los conteos a una columna recién creada en la tabla areas.
db.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 10000 non-null object
1 longitude 10000 non-null float64
2 latitude 10000 non-null float64
3 date_taken 10000 non-null object
4 photo/video_page_url 10000 non-null object
5 x 10000 non-null float64
6 y 10000 non-null float64
dtypes: float64(4), object(3)
memory usage: 547.0+ KB
Mallas regulares: Hex-binning#
A veces no tenemos ninguna capa de polígonos para usar o las que tenemos no son particularmente adecuadas para agregar puntos en ellas. En estos casos, una alternativa sensata es crear una topología artificial de polígonos que podamos utilizar para agregar puntos. Hay varias formas de hacer esto, pero la más común es crear una cuadrícula de hexágonos. Esto proporciona una topología regular (cada polígono tiene el mismo tamaño y forma) que, a diferencia de los círculos, agota todo el espacio sin superposiciones y tiene más bordes que los cuadrados, lo que alivia los problemas de borde.
Python tiene una forma simplificada de crear esta capa de hexágonos y agregar puntos en ella de una sola vez gracias al método hexbin, que está disponible en cada objeto de eje (por ejemplo, ax). Primero veamos cómo podrías crear un mapa solo de la capa de hexágonos:
Una solución para evitar el desorden se relaciona con lo que mencionamos anteriormente como el paso de “tablas a superficies”. Ahora podemos reformular este enfoque como un histograma espacial o bidimensional. Aquí, generamos una cuadrícula regular (ya sea cuadrada o hexagonal), contamos cuántos puntos caen dentro de cada celda de la cuadrícula y la presentamos como lo haríamos con cualquier otro coropleta. Esto es atractivo porque es simple, intuitivo y, si la cuadrícula es lo suficientemente fina, elimina algunas de las distorsiones de área que los coropletas pueden inducir. Para esta ilustración, usemos el agrupamiento hexagonal (a veces llamado hexbin) porque tiene propiedades ligeramente mejores que las cuadrículas cuadradas, como menos distorsión de forma y una conectividad más regular entre las celdas. Crear un histograma bidimensional con hexbin es sencillo en Python utilizando la función hexbin:
import matplotlib.pyplot as plt
# Set up figure and axis
f, ax = plt.subplots(1, figsize=(12, 9))
# Generate and add hexbin with 50 hexagons in each dimension, no borderlines, half transparency, and the reverse viridis colormap
hb = ax.hexbin(
db['x'],
db['y'],
gridsize=50,
linewidths=0,
alpha=0.5,
cmap='viridis_r'
)
# Add basemap
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
# Add colorbar
plt.colorbar(hb)
# Remove axes
ax.set_axis_off()
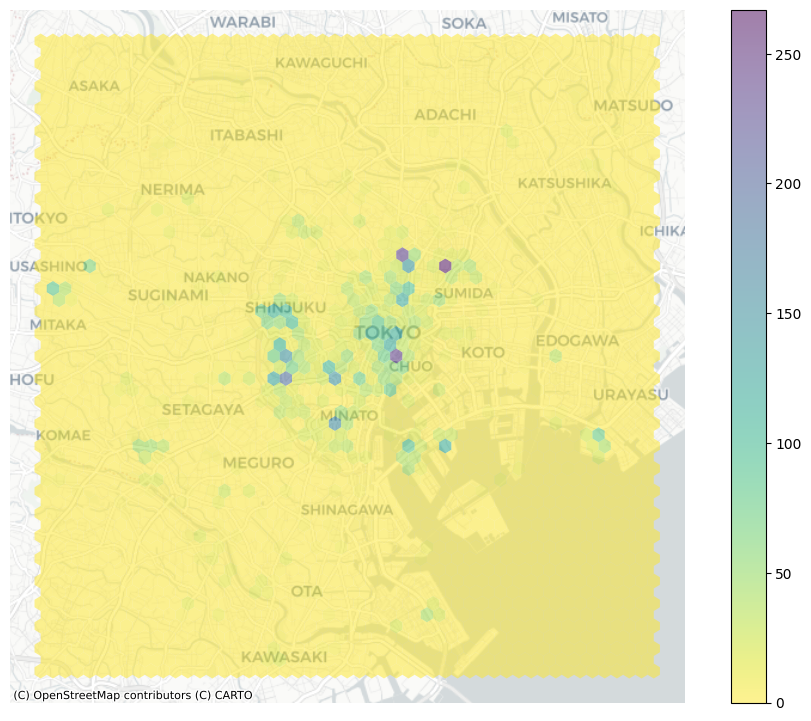
Ahora es claro que la mayoría de las fotografías se relacionan con áreas mucho más localizadas y que el mapa anterior estaba ocultando esto. Observa cómo solo hace falta configurar la figura y llamar a hexbin directamente usando el conjunto de columnas de coordenadas (db["longitude"] y db["latitude"]). Los argumentos adicionales que incluimos son el número de hexágonos por eje (gridsize, 50 para una capa de 50 por 50), y la transparencia que queremos (80%). Además, incluimos una barra de color para tener una idea de cómo se mapean los conteos a los colores. Ten en cuenta que necesitamos pasar el nombre del objeto que incluye el hexbin (hb en nuestro caso), pero recuerda que esto es opcional, no siempre necesitas crear uno.
Estimación de Densidad de Kernel (KDE)#
El uso de un agrupamiento hexagonal puede ser una solución rápida cuando no tenemos una buena capa de polígonos para superponer los puntos directamente, y algunas de sus propiedades, como el tamaño igual de cada polígono, pueden ayudar a aliviar algunos de los problemas con una topología irregular “mala” (una que no se ajusta al proceso generador de puntos subyacente). Sin embargo, no resuelve el problema de la unidad de área modificable (M.A.U.P.). Al final del día, seguimos imponiendo líneas de límite arbitrarias y agregando datos en función de ellas, por lo que la posibilidad de desajuste con la distribución subyacente del patrón de puntos es muy real.
Una forma de evitar este problema es evitar la agregación en otra geografía por completo. En su lugar, podemos intentar estimar la distribución de probabilidad continua observada. El método más comúnmente utilizado para esto es el llamado estimador de densidad de kernel (KDE). La idea detrás de los KDE es contar el número de puntos de una manera continua. En lugar de usar un conteo discreto, donde se incluye un punto en el conteo si está dentro de ciertos límites y se ignora de lo contrario, los KDE usan funciones (kernels) que incluyen puntos pero les asignan diferentes pesos a cada uno dependiendo de qué tan lejos está la ubicación en la que estamos contando el punto.
El algoritmo real para estimar una densidad de kernel no es trivial, pero su aplicación en Python se simplifica bastante con el uso de Seaborn. Sin embargo, los KDE son bastante intensivos en términos computacionales. Cuando tienes un patrón de puntos grande como en el ejemplo de tokyo (10,000 puntos), su cálculo puede tomar un poco de tiempo. Para solucionar este problema, creamos un subconjunto aleatorio, que conserva la estructura general del patrón, pero con muchos menos puntos. Tomemos un subconjunto de 1,000 puntos aleatorios de nuestra tabla original:
# Set up figure and axis
f, ax = plt.subplots(1, figsize=(9, 9))
sbn.kdeplot(x=db['x'],y=db['y'],n_levels=30,fill=True,alpha=0.55,cmap='viridis_r')
# Add basemap
ctx.add_basemap(ax,source=ctx.providers.CartoDB.Positron)
# Remove axes
ax.set_axis_off();
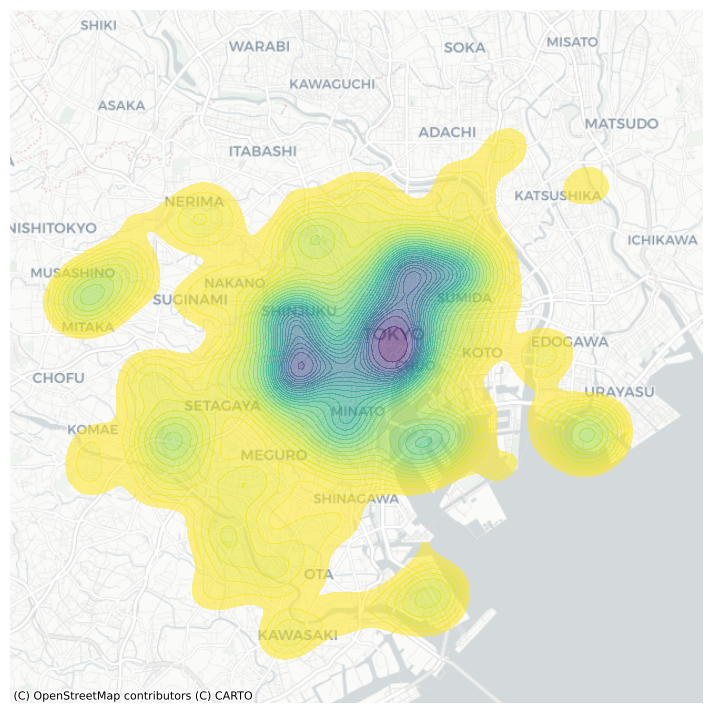
El resultado es una salida más suave que captura la misma estructura del hexbin, pero que “suaviza” las transiciones entre diferentes áreas. Esto proporciona una mejor generalización de la probabilidad teórica de que una foto podría ocurrir en cualquier punto dado. Esto es útil en algunos casos, pero principalmente es útil para evitar las restricciones impuestas por una cuadrícula regular de hexágonos o cuadrados.
Seaborn simplifica enormemente el proceso y lo reduce a una sola línea. El método sns.kdeplot (que también podemos usar para crear un KDE de una sola variable) toma las coordenadas X e Y de los puntos como los únicos atributos obligatorios. Además, especificamos el número de niveles que queremos que tenga el degradado de color (n_levels), si queremos colorear el espacio entre cada nivel (shade, sí), y el colormap de nuestra elección.
Centrografía#
La centrografía es el análisis de la centralidad en un patrón de puntos. Por “centralidad”, nos referimos a la ubicación general y dispersión del patrón. Si el hexbin anterior puede verse como un “histograma espacial”, la centrografía es el equivalente en patrones de puntos de las medidas de tendencia central, como la media. Estas medidas son útiles porque nos permiten resumir distribuciones espaciales en conjuntos más pequeños de información (por ejemplo, un solo punto). Se utilizan muchos índices diferentes en la centrografía para proporcionar una indicación de “dónde” se encuentra un patrón de puntos, qué tan agrupado está el patrón alrededor de su centro, o qué tan irregular es su forma.
from pointpats import centrography
mean_center = centrography.mean_center(db[['x', 'y']])
med_center = centrography.euclidean_median(db[['x', 'y']])
# Generate scatter plot
joint_axes = sbn.jointplot(x='x', y='y',data=db,s=0.75,height=9)
# Add mean point and marginal lines
joint_axes.ax_joint.scatter(*mean_center, color='red', marker='x', s=50, label='Mean Center')
joint_axes.ax_marg_x.axvline(mean_center[0], color='red')
joint_axes.ax_marg_y.axhline(mean_center[1], color='red')
# Add median point and marginal lines
joint_axes.ax_joint.scatter(*med_center, color='limegreen', marker='o', s=50, label='Median Center')
joint_axes.ax_marg_x.axvline(med_center[0], color='limegreen')
joint_axes.ax_marg_y.axhline(med_center[1], color='limegreen')
# Legend
joint_axes.ax_joint.legend()
# Add basemap
ctx.add_basemap(joint_axes.ax_joint,source=ctx.providers.CartoDB.Positron)
# Clean axes
joint_axes.ax_joint.set_axis_off()
# Display
plt.show()
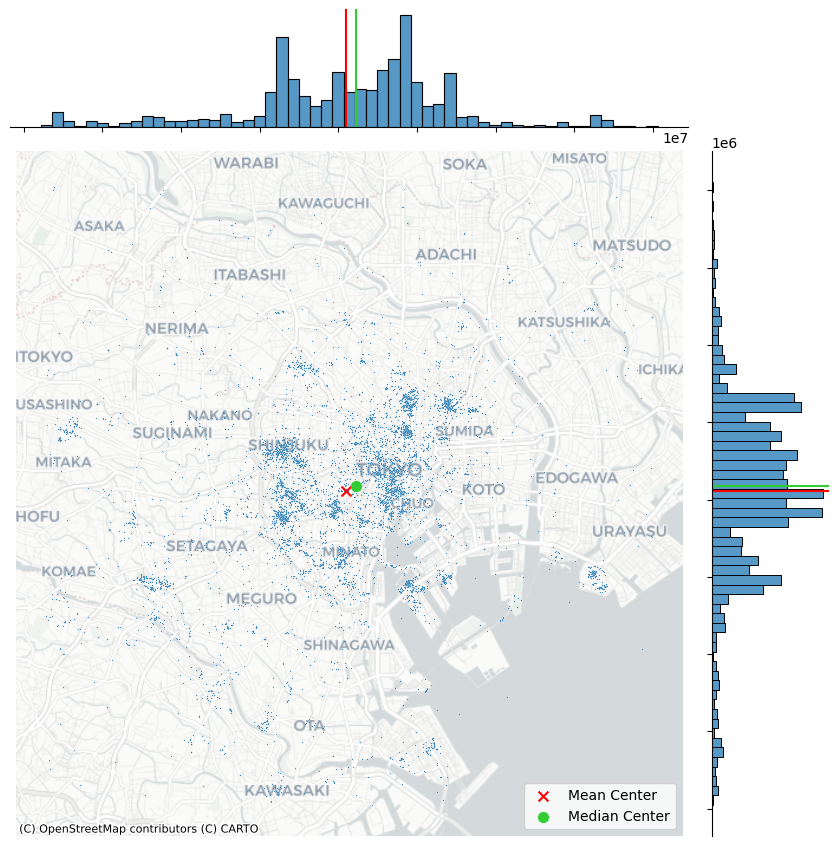
La discrepancia entre los dos centros se debe a la asimetría; hay muchos “grupos” de fotos en el oeste y sur de Tokio, mientras que el norte y el este de Tokio están densamente poblados, pero la densidad disminuye muy rápidamente. Por lo tanto, los grupos de fotos más alejados tiran del centro medio hacia el oeste y sur, en relación con el centro mediano.
Dispersión#
Una medida de dispersión que es común en la centrografía es la distancia estándar. Esta medida proporciona la distancia promedio desde el centro de la nube de puntos (como se mide desde el centro de masa). Esto también es simple de calcular utilizando pointpats, con la función std_distance:
centrography.std_distance(db[['x','y']])
8778.218564382098
Esto significa que, en promedio, las fotos se toman a unos 8800 metros del centro medio.
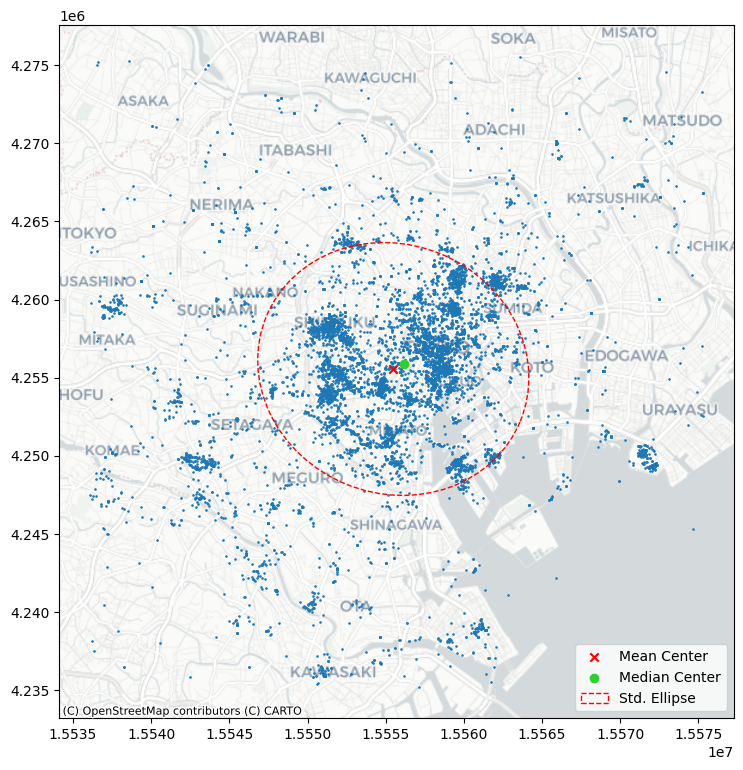
Otra visualización útil es la elipse de desviación estándar, o elipse estándar. Esta es una elipse trazada a partir de los datos que refleja tanto su centro como su dispersión. Para visualizar esto, primero calculamos los ejes y la rotación utilizando la función ellipse en pointpats:
major, minor, rotation = centrography.ellipse(db[['x','y']])
from matplotlib.patches import Ellipse
import numpy as np
# Set up figure and axis
f, ax = plt.subplots(1, figsize=(9, 9))
# Plot photograph points
ax.scatter(db['x'], db['y'], s=0.75)
ax.scatter(*mean_center, color='red', marker='x', label='Mean Center')
ax.scatter(*med_center, color='limegreen', marker='o', label='Median Center')
# Construct the standard ellipse using matplotlib
ellipse = Ellipse(xy=mean_center, # center the ellipse on our mean center
width=major*2, # centrography.ellipse only gives half the axis
height=minor*2,
angle = np.rad2deg(rotation), # Angles for this are in degrees, not radians
facecolor='none',
edgecolor='red', linestyle='--',
label='Std. Ellipse')
ax.add_patch(ellipse)
ax.legend()
# Display
# Add basemap
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
plt.show()
Extensión#
La última colección de medidas de centrografía que discutiremos caracteriza la extensión de una nube de puntos. Cuatro formas son útiles y reflejan distintos niveles de cómo “ajustan” el patrón.
A continuación, repasaremos cómo construir cada ejemplo y visualizarlos al final. Para que sea más claro, usaremos las fotos de Flickr del usuario más prolífico en el conjunto de datos (ID: 95795770) para mostrar lo diferentes que pueden ser estos resultados.
user = db.query('user_id == "95795770@N00"')
coordinates = user[['x','y']].values
Primero, calcularemos el envolvente convexo (convex hull), que es la forma convexa más ajustada que encierra las fotos del usuario. Por convexa, nos referimos a que la forma nunca “retrocede” sobre sí misma; no tiene depresiones, valles, crestas o agujeros. Todos sus ángulos interiores son menores de 180 grados. Esto se calcula usando el método centrography.hull.
convex_hull_vertices = centrography.hull(coordinates)
En segundo lugar, calcularemos la forma alfa (alpha shape), que puede entenderse como una versión más “ajustada” del envolvente convexo. Una forma de pensar en el envolvente convexo es que es el espacio que queda cuando se rueda una bola o círculo realmente grande alrededor de la forma. La bola es tan grande en relación con la forma que su radio es en realidad infinito, ¡y las líneas que forman el envolvente convexo son líneas rectas!
En contraste, puedes pensar en la forma alfa como el espacio formado al rodar bolas pequeñas alrededor de la forma. Dado que la bola es más pequeña, rueda hacia las hendiduras y valles creados entre los puntos. A medida que esa bola se hace más grande, la forma alfa se convierte en el envolvente convexo. Pero, para bolas pequeñas, la forma puede volverse muy ajustada. De hecho, si el alfa es demasiado pequeño, “resbala” entre los puntos, lo que da como resultado más de un envolvente. Por lo tanto, el paquete pysal tiene una función alpha_shape_auto para encontrar la forma alfa única más pequeña, para que no tengas que adivinar qué tan grande debe ser la bola.
import libpysal
alpha_shape, alpha, circs = libpysal.cg.alpha_shape_auto(coordinates, return_circles=True)
alpha_shape

Para ilustrar, la figura a continuación muestra la forma alfa única más ajustada en verde y los puntos originales en negro. Los círculos de “delimitación” mostrados en la figura tienen un radio de \(8652\) metros. Los círculos están trazados donde nuestro disco de “delimitación” toca dos o tres de los puntos en la nube de puntos. Puedes ver que los círculos “recortan” el envolvente convexo, mostrado en líneas azules discontinuas, hasta que tocan dos (o tres) puntos. Si fueran más ajustados, el círculo desconectaría uno de los puntos en el límite de la forma alfa.
from descartes import PolygonPatch #to plot the alpha shape easily
f,ax = plt.subplots(1,1, figsize=(9,9))
# Plot a green alpha shape
ax.add_patch(
PolygonPatch(
alpha_shape,
edgecolor='green',
facecolor='green',
alpha=.2,
label = 'Tighest single alpha shape'
)
)
# Include the points for our prolific user in black
ax.scatter(
*coordinates.T, color='k', marker='.', label='Source Points'
)
# plot the circles forming the boundary of the alpha shape
for i, circle in enumerate(circs):
# only label the first circle of its kind
if i == 0:
label = 'Bounding Circles'
else:
label = None
ax.add_patch(
plt.Circle(
circle,
radius=alpha,
facecolor='none',
edgecolor='r',
label=label
)
)
# add a blue convex hull
ax.add_patch(
plt.Polygon(
convex_hull_vertices,
closed=True,
edgecolor='blue',
facecolor='none',
linestyle=':',
linewidth=2,
label='Convex Hull'
)
)
# Add basemap
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
plt.legend();
Aleatoriedad y agrupamiento#
Más allá de las preguntas sobre centralidad y extensión, las estadísticas espaciales sobre patrones de puntos a menudo se preocupan por qué tan uniforme es la distribución de puntos. Con esto nos referimos a si los puntos tienden a agruparse entre sí o a dispersarse uniformemente por el área de estudio. Preguntas como esta se refieren a la intensidad o dispersión del patrón de puntos en general. En el lenguaje técnico de los últimos dos capítulos, este enfoque se asemeja a los objetivos que examinamos cuando introdujimos la autocorrelación espacial global: ¿cuál es el grado general de agrupamiento que observamos en el patrón? Las estadísticas espaciales han dedicado mucho esfuerzo a comprender este tipo de agrupamiento. Esta sección cubrirá métodos útiles para identificar el agrupamiento en patrones de puntos.
El primer conjunto de técnicas, las estadísticas de cuadrante, reciben su nombre por su enfoque de dividir los datos en áreas pequeñas (cuadrantes). Una vez creados, estos “recipientes” se utilizan para examinar la uniformidad de los conteos entre ellos. El segundo conjunto de técnicas se deriva de Ripley (1988) e involucra la medición de la distancia entre puntos en un patrón de puntos.
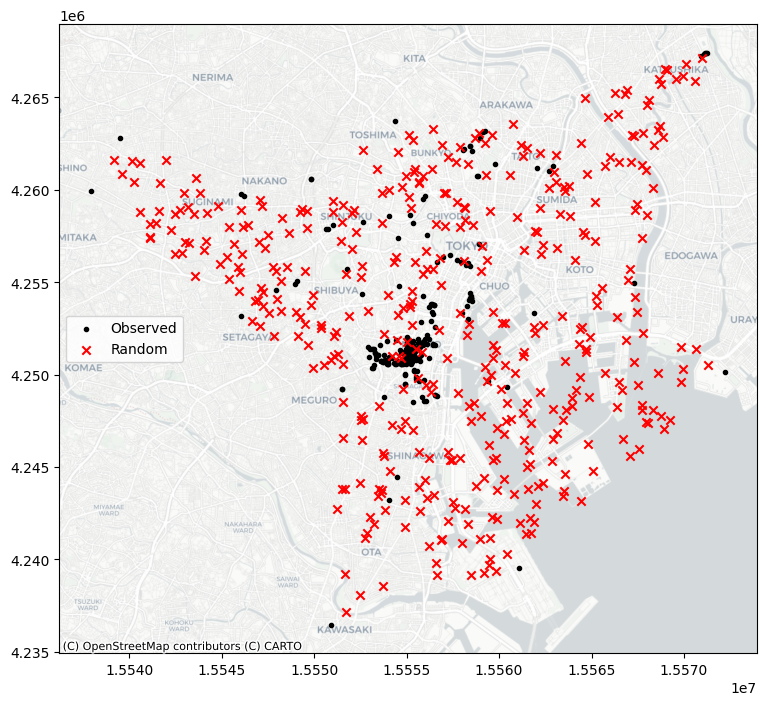
Para fines de ilustración, también es útil proporcionar un patrón derivado de un proceso completamente aleatorio en el espacio. Es decir, la ubicación y el número de puntos es totalmente aleatorio; no hay ni agrupamiento ni dispersión. En el análisis de patrones de puntos, esto se conoce como un proceso de puntos de Poisson.
Para simular estos procesos a partir de un conjunto de puntos dado, puedes usar el módulo pointpats.random.
from pointpats import distance_statistics, QStatistic, random, PointPattern
random_pattern = random.poisson(coordinates, size=len(coordinates))
f,ax = plt.subplots(1, figsize=(9, 9))
plt.scatter(*coordinates.T, color='k', marker='.', label='Observed photographs')
plt.scatter(*random_pattern.T, color='r', marker='x', label='Random')
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
ax.legend(ncol=1, loc='center left')
plt.show()
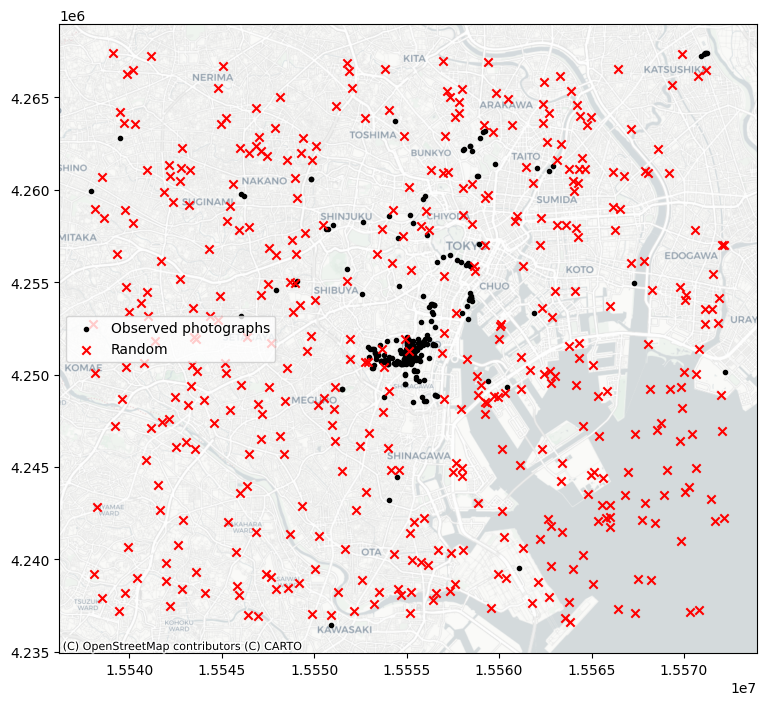
Como puedes ver, la simulación (por defecto) funciona con el cuadro delimitador del patrón de puntos de entrada. Para simular a partir de áreas más restringidas formadas por el patrón de puntos, ¡pasa esos envolventes al simulador! Por ejemplo, para generar un patrón aleatorio dentro de las formas alfa:
random_pattern_ashape = random.poisson(alpha_shape, size=len(coordinates))
f,ax = plt.subplots(1, figsize=(9, 9))
plt.scatter(*coordinates.T, color='k', marker='.', label='Observed')
plt.scatter(*random_pattern_ashape.T, color='r', marker='x', label='Random')
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
ax.legend(ncol=1, loc='center left')
plt.show()
Estadísticas de cuadrantes#
Las estadísticas de cuadrantes examinan la distribución espacial de puntos en un área en términos del conteo de observaciones que caen dentro de una celda dada. Al examinar si las observaciones están distribuidas uniformemente en las celdas, el enfoque de cuadrantes busca estimar si los puntos están dispersos o si están agrupados en unas pocas celdas. Estrictamente hablando, las estadísticas de cuadrantes examinan la uniformidad de la distribución sobre las celdas utilizando una prueba estadística \(\chi^2\), común en el análisis de tablas de contingencia.
En el paquete pointpats, puedes visualizar los resultados usando el siguiente método QStatistic.plot(). Esto muestra la cuadrícula utilizada para contar los eventos, así como el patrón subyacente:
qstat = QStatistic(coordinates, nx = 2, ny = 2)
qstat.plot()
<Axes: title={'center': 'Quadrat Count'}>
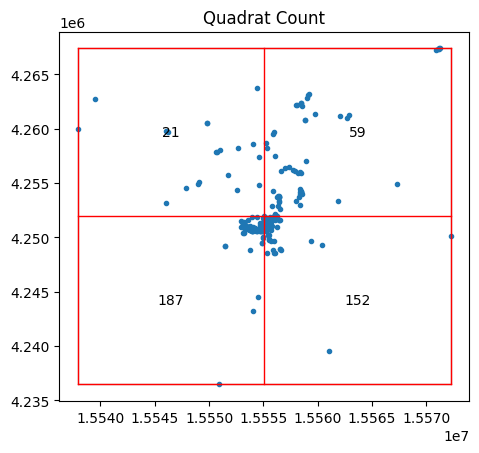
En este caso, para la configuración predeterminada de una cuadrícula de tres por tres que abarca el patrón de puntos, vemos que la celda central tiene más de 350 observaciones, pero las celdas circundantes tienen muchas menos fotografías de Flickr. Esto significa que la prueba de chi-cuadrado (que compara cuán probable es esta distribución si los conteos en las celdas fueran uniformes) será estadísticamente significativa, con un valor p muy pequeño:
qstat.chi2_pvalue
3.1046953044368864e-37
En contraste, nuestro proceso de puntos totalmente aleatorio tendrá casi la misma cantidad de puntos en cada celda:
qstat_null = QStatistic(random_pattern)
qstat_null.plot()
<Axes: title={'center': 'Quadrat Count'}>
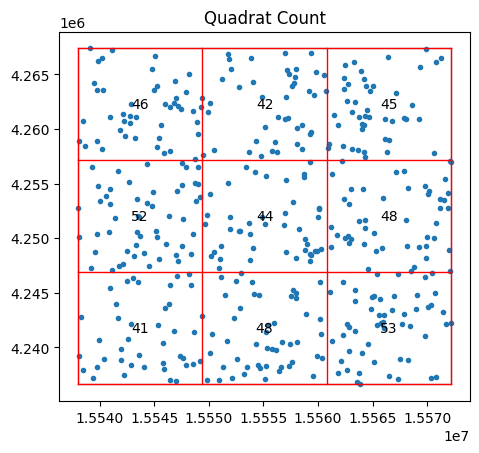
qstat_null.chi2_pvalue
0.9389143237146387
Alfabeto de funciones de Ripley#
El segundo grupo de estadísticas espaciales que consideramos se centra en las distribuciones de dos cantidades en un patrón de puntos: las distancias al vecino más cercano y lo que denominamos “gaps” en el patrón. Estas derivan del trabajo seminal de Ripley (1991) sobre cómo caracterizar el agrupamiento o la co-ubicación en patrones de puntos. Cada una de estas funciones caracteriza un aspecto del patrón de puntos a medida que aumentamos el rango de distancia desde cada punto para calcularlas.
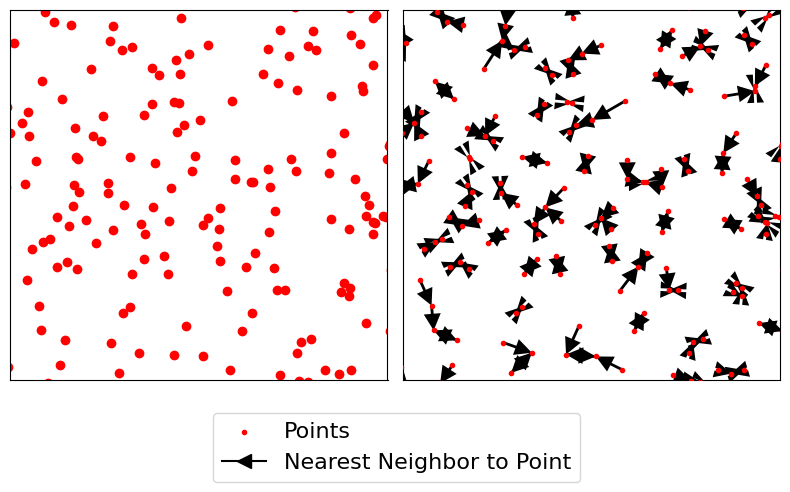
La primera función, \(G\) de Ripley, se enfoca en la distribución de las distancias al vecino más cercano. Es decir, la función \(G\) resume las distancias entre cada punto en el patrón y su vecino más cercano. En el gráfico a continuación, esta lógica del vecino más cercano se visualiza con los puntos rojos que son una vista detallada del patrón de puntos y las flechas negras que indican el vecino más cercano de cada punto. Observa que a veces dos puntos son mutuamente vecinos más cercanos (por lo que tienen flechas en ambas direcciones), pero algunos no lo son.
# this code should be hidden in the book, and only the plot visible!
f,ax = plt.subplots(1,2,figsize=(8,4), sharex=True, sharey=True)
ax[0].scatter(*random_pattern.T, color='red')
ax[1].scatter(*random_pattern.T, color='red',
zorder=100, marker='.', label='Points')
nn_ixs, nn_ds = PointPattern(random_pattern).knn(1)
first = True
for coord, nn_ix, nn_d in zip(random_pattern, nn_ixs, nn_ds):
dx, dy = random_pattern[nn_ix].squeeze() - coord
arrow = ax[1].arrow(*coord, dx,dy,
length_includes_head=True,
overhang=0, head_length=300*3,
head_width=300*3, width=50*3,
linewidth=0, facecolor='k',
head_starts_at_zero=False)
if first:
plt.plot((1e100, 1e101), (0,1), color='k',
marker='<', markersize=10,
label='Nearest Neighbor to Point')
first = False
ax[0].axis([1.554e7, 1.556e7, 4240000, 4260000])
ax[0].set_xticklabels([])
ax[0].set_yticklabels([])
ax[0].set_xticks([])
ax[0].set_yticks([])
f.tight_layout()
ax[1].legend(bbox_to_anchor = (.5,-.06), fontsize=16)
plt.show()
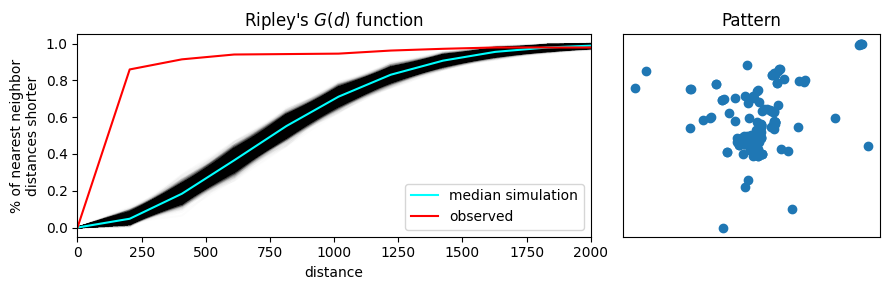
Ripley’s \(G\) lleva un registro de la proporción de puntos cuyo vecino más cercano se encuentra dentro de un umbral de distancia dado y traza ese porcentaje acumulado contra los radios de distancia crecientes. La distribución de este porcentaje acumulado tiene una forma distintiva bajo procesos completamente aleatorios en el espacio. La intuición detrás de Ripley’s \(G\) es la siguiente: podemos aprender qué tan similar es nuestro patrón a uno aleatorio en el espacio calculando la distribución acumulada de las distancias al vecino más cercano sobre umbrales de distancia crecientes y comparándola con la de un conjunto de patrones simulados que siguen un proceso espacialmente aleatorio conocido. Generalmente, se utiliza un proceso de puntos de Poisson espacial como distribución de referencia.
Para hacer esto en el paquete pointpats, podemos utilizar la función g_test, que calcula tanto la función G para los datos empíricos como estas réplicas hipotéticas bajo un proceso completamente aleatorio en el espacio.
g_test = distance_statistics.g_test(coordinates, support=40, keep_simulations=True)
Pensando en estas distribuciones de distancias, un patrón “agrupado” debe tener más puntos cerca unos de otros en comparación con un patrón “disperso”; y un patrón completamente aleatorio debería tener algo intermedio. Por lo tanto, si la función \(G\) aumenta rápidamente con la distancia, probablemente tenemos un patrón agrupado. Si aumenta lentamente con la distancia, tenemos un patrón disperso. Algo intermedio será difícil de distinguir del puro azar.
Podemos visualizar esto a continuación. A la izquierda, trazamos la función \(G(d)\), con la distancia al punto (\(d\)) en el eje horizontal y la fracción de distancias al vecino más cercano menores que \(d\) en el eje derecho. En rojo, se muestra la distribución acumulada empírica de las distancias al vecino más cercano. En azul, se muestran las simulaciones (como el patrón random mostrado en la sección anterior). La línea azul brillante representa el promedio de todas las simulaciones, y la banda azul oscuro/negro a su alrededor representa el 95% de las simulaciones.
En este gráfico, vemos que la función empírica roja aumenta mucho más rápido que los patrones simulados completamente aleatorios en el espacio. Esto significa que el patrón observado de las fotografías de Flickr de este usuario está más cerca de sus vecinos más cercanos de lo que se esperaría en un patrón completamente aleatorio. El patrón está agrupado.
f,ax = plt.subplots(1,2,figsize=(9,3),gridspec_kw=dict(width_ratios=(6,3)))
# plot all the simulations with very fine lines
ax[0].plot(g_test.support, g_test.simulations.T, color='k', alpha=.01)
# and show the average of simulations
ax[0].plot(g_test.support, np.median(g_test.simulations, axis=0), color='cyan',label='median simulation')
# and the observed pattern's G function
ax[0].plot(g_test.support, g_test.statistic, label = 'observed', color='red')
# clean up labels and axes
ax[0].set_xlabel('distance')
ax[0].set_ylabel('% of nearest neighbor\ndistances shorter')
ax[0].legend()
ax[0].set_xlim(0,2000)
ax[0].set_title(r"Ripley's $G(d)$ function")
# plot the pattern itself on the next frame
ax[1].scatter(*coordinates.T)
# and clean up labels and axes there, too
ax[1].set_xticks([])
ax[1].set_yticks([])
ax[1].set_xticklabels([])
ax[1].set_yticklabels([])
ax[1].set_title('Pattern')
f.tight_layout()
plt.show()
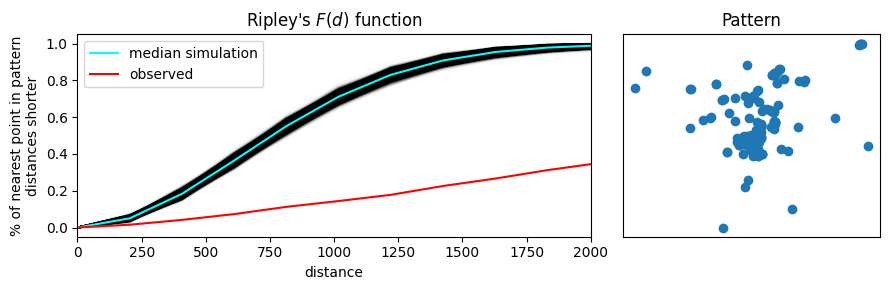
La segunda función que introducimos es Ripley’s \(F\). Mientras que la función \(G\) analiza la distancia entre los puntos en el patrón, la función F trabaja analizando la distancia hacia los puntos en el patrón desde ubicaciones en el espacio vacío. Por eso la función \(F\) se llama la “función de espacio vacío”, ya que caracteriza la distancia típica desde puntos arbitrarios en el espacio vacío hasta el patrón de puntos. Más explícitamente, la función \(F\) acumula, para un rango de distancias creciente, el porcentaje de puntos que se pueden encontrar dentro de ese rango a partir de un patrón de puntos aleatorio generado dentro de la extensión del patrón observado. Si el patrón tiene grandes huecos o áreas vacías, la función \(F\) aumentará lentamente. Pero, si el patrón está muy disperso, la función \(F\) aumentará rápidamente. La forma de esta distribución acumulada luego se compara con aquellas construidas calculando la misma distribución acumulada entre el patrón aleatorio y otro patrón aleatorio adicional generado en cada paso de la simulación.
Podemos utilizar herramientas similares para investigar la función \(F\), ya que es matemáticamente muy similar a la función \(G\). Esto se implementa de manera idéntica usando la función f_test en pointpats. Dado que la función \(F\) estimada para el patrón observado aumenta mucho más lentamente que las funciones \(F\) para los patrones simulados, podemos estar seguros de que hay muchos huecos en nuestro patrón; es decir, el patrón está agrupado.
f_test = distance_statistics.f_test(coordinates, support=40, keep_simulations=True)
f,ax = plt.subplots(1,2,figsize=(9,3), gridspec_kw=dict(width_ratios=(6,3)))
# plot all the simulations with very fine lines
ax[0].plot(f_test.support, f_test.simulations.T, color='k', alpha=.01)
# and show the average of simulations
ax[0].plot(f_test.support, np.median(f_test.simulations, axis=0), color='cyan',label='median simulation')
# and the observed pattern's F function
ax[0].plot(f_test.support, f_test.statistic, label = 'observed', color='red')
# clean up labels and axes
ax[0].set_xlabel('distance')
ax[0].set_ylabel('% of nearest point in pattern\ndistances shorter')
ax[0].legend()
ax[0].set_xlim(0,2000)
ax[0].set_title(r"Ripley's $F(d)$ function")
# plot the pattern itself on the next frame
ax[1].scatter(*coordinates.T)
# and clean up labels and axes there, too
ax[1].set_xticks([])
ax[1].set_yticks([])
ax[1].set_xticklabels([])
ax[1].set_yticklabels([])
ax[1].set_title('Pattern')
f.tight_layout()
plt.show()
Identificación de agrupamientos (clusters)#
Las dos secciones anteriores sobre el análisis espacial exploratorio de patrones de puntos proporcionan métodos para caracterizar si los patrones de puntos están dispersos o agrupados en el espacio. Otra forma de ver el contenido de esas secciones es que nos ayudan a explorar el grado general de agrupamiento. Sin embargo, saber que un patrón de puntos está agrupado no necesariamente nos dice dónde se encuentra ese (conjunto de) agrupamiento(s). Para hacer esto, necesitamos cambiar a un método capaz de identificar áreas con alta densidad de puntos dentro de nuestro patrón. En otras palabras, en esta sección nos centramos en la existencia y ubicación de los agrupamientos. Esta distinción entre agrupamiento y agrupamientos de puntos es análoga a la discutida en el contexto de la autocorrelación espacial. La noción es la misma, las diferencias en las técnicas que examinamos en cada parte del libro están relacionadas con la naturaleza única de los puntos a la que nos referimos al principio del cuaderno. Recuerda que, mientras que los métodos que exploramos en los cuadernos anteriores toman la ubicación de los objetos espaciales (puntos, líneas, polígonos) como dadas y se enfocan en comprender las configuraciones de valores dentro de esas ubicaciones; los métodos discutidos en este capítulo entienden los puntos como eventos que ocurren en ubicaciones particulares pero que podrían ocurrir en un conjunto mucho más amplio de lugares. Tener en cuenta esta relevancia subyacente de la ubicación del objeto en sí es lo que hace que las técnicas en este cuaderno sean distintas.
Agrupamiento DBSCAN#
DBSCAN (Agrupamiento Basado en Densidad de Aplicaciones) es un método de agrupamiento basado en la densidad, lo que significa que los puntos que están estrechamente agrupados se asignan al mismo grupo y se les da el mismo ID. El algoritmo DBSCAN tiene dos parámetros que el usuario necesita especificar:
ε — La distancia máxima entre puntos para ser considerados dentro del mismo grupo.
minPts — El número mínimo de puntos necesarios para formar un grupo.
En resumen, todos los grupos de al menos minPts puntos, donde cada punto está a una distancia ε o menos de al menos otro punto en el grupo, se consideran grupos separados y se les asignan IDs únicos. Todos los demás puntos se consideran “ruido” y no se les asigna un ID.
DBSCAN es un algoritmo ampliamente utilizado que se originó en el área de descubrimiento de conocimiento y aprendizaje automático, y desde entonces se ha extendido a muchas áreas, incluida el análisis de puntos espaciales. En parte, su popularidad radica en su simplicidad intelectual y viabilidad computacional. De alguna manera, podemos pensar en DBSCAN como un equivalente para patrones de puntos de las estadísticas locales. Sin embargo, difieren en aspectos fundamentales. A diferencia de las estadísticas locales que hemos visto anteriormente, DBSCAN no se basa en un marco inferencial, sino que es un algoritmo determinista. Esto implica que, a diferencia de las medidas vistas antes, no podremos estimar una medida del grado en que los grupos encontrados son compatibles con casos de aleatoriedad espacial.
Desde el punto de vista de DBSCAN, un grupo es una concentración de al menos m puntos, cada uno de ellos dentro de una distancia de r de al menos otro punto en el grupo. Siguiendo esta definición, el algoritmo clasifica cada punto en nuestro patrón en tres categorías:
Ruido, para aquellos puntos fuera de un grupo.
Núcleos, para aquellos puntos dentro de un grupo con al menos
mpuntos en el grupo dentro de la distanciar.Bordes, para puntos dentro de un grupo con menos de
mpuntos en el grupo dentro de la distanciar.
La flexibilidad (pero también algunas de las limitaciones) del algoritmo reside en que tanto m como r deben ser predefinidos por el usuario antes de ejecutar DBSCAN. Este es un punto crítico, ya que su valor puede influir significativamente en el resultado final. Antes de explorar esto con mayor profundidad, hagamos una primera ejecución del cálculo de DBSCAN en Python:
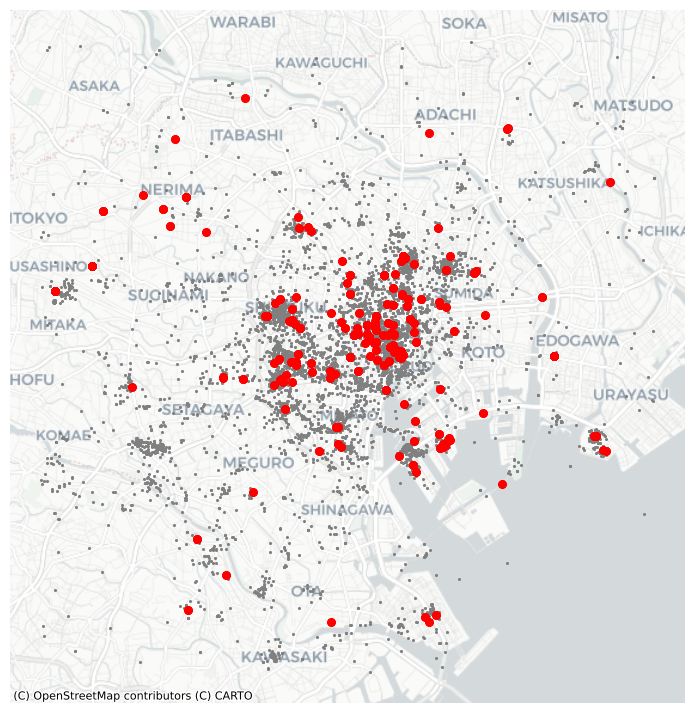
from sklearn.cluster import DBSCAN
# Define DBSCAN
clusterer = DBSCAN()
# Fit to our data
clusterer.fit(db[["x", "y"]])
DBSCAN()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DBSCAN()
import pandas as pd
lbls = pd.Series(clusterer.labels_, index=db.index)
# Setup figure and axis
f, ax = plt.subplots(1, figsize=(9, 9))
# Subset points that are not part of any cluster (noise)
noise = db.loc[lbls==-1, ['x', 'y']]
# Plot noise in grey
ax.scatter(noise['x'], noise['y'], c='grey', s=5, linewidth=0)
# Plot all points that are not noise in red
# NOTE how this is done through some fancy indexing, where
# we take the index of all points (tw) and substract from
# it the index of those that are noise
ax.scatter(db.loc[db.index.difference(noise.index), 'x'], \
db.loc[db.index.difference(noise.index), 'y'], \
c='red', linewidth=0)
# Add basemap
ctx.add_basemap(
ax,
source=ctx.providers.CartoDB.Positron
)
# Remove axes
ax.set_axis_off()
# Display the figure
plt.show()
Actividades#
Centrografía: Usando el dataset de deslizamientos del área de estudio (puntos centroides de las subcuencas ponderados por número de deslizamientos), calcula: (a) el centro medio, (b) la distancia estándar y (c) la elipse de desviación estándar. Mapea estos elementos sobre el área de estudio e interpreta la distribución espacial.
KDE con distintos anchos de banda: Aplica la estimación de densidad de kernel (KDE) al mismo dataset con tres anchos de banda diferentes (pequeño, mediano, grande). ¿Cómo cambia la interpretación de los “hotspots” de deslizamientos con cada ancho de banda? ¿Cuál sería el más apropiado y por qué?
Funciones G y F: Para un subconjunto de 100 puntos del dataset, calcula las funciones G y F. Grafica las curvas observadas frente a las esperadas bajo un proceso de Poisson homogéneo. ¿Qué indican estas curvas sobre la naturaleza del proceso (agrupado, aleatorio o regular)?
DBSCAN: Aplica el algoritmo DBSCAN al dataset de centroides de subcuencas con al menos tres combinaciones de parámetros (
eps,min_samples). Para cada combinación, reporta: número de clusters encontrados, porcentaje de puntos clasificados como ruido, y un mapa de los clusters. ¿Qué combinación de parámetros produce la segmentación más interpretable geomorfológicamente?
Recursos adicionales#
Documentación oficial#
Lecturas recomendadas#
Diggle, P. J. (2003). Statistical Analysis of Spatial Point Patterns (2nd ed.). Arnold.
Ripley, B. D. (1976). The second-order analysis of stationary point processes. Journal of Applied Probability, 13(2), 255–266.
Ester, M. et al. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. KDD-96 Proceedings, 226–231.
Schabenberger, O. & Gotway, C. A. (2005). Statistical Methods for Spatial Data Analysis. CRC Press.