Créditos: El contenido de este cuaderno ha sido tomado de varias fuentes, pero especialmente de Dani Arribas-Bel - University of Liverpool & Sergio Rey - Center for Geospatial Sciences, University of California, Riverside. El compilador se disculpa por cualquier omisión involuntaria y estaría encantado de agregar un reconocimiento.
Visualización de datos discretos#
Coropletas#
Los mapas coropléticos juegan un papel importante en la ciencia de datos geográficos, ya que nos permiten mostrar atributos o variables no geográficas en un mapa geográfico. La palabra coroplético proviene de la raíz “coro”, que significa “región”. Como tal, los mapas coropléticos representan datos a nivel de región y son apropiados para datos de unidades areales donde cada observación combina un valor de un atributo y una figura geométrica, generalmente un polígono. Los mapas coropléticos derivan de una era anterior en la que los cartógrafos enfrentaban limitaciones tecnológicas que impedían el uso de mapas sin clasificar, donde cada valor único de un atributo podría estar representado por un símbolo o color distinto. En su lugar, los valores de los atributos se agrupaban en un número menor de clases, usualmente no más de 12. Cada clase se asociaba con un símbolo único que, a su vez, se aplicaba a todas las observaciones con valores de atributos dentro de esa clase.
Aunque hoy en día estas limitaciones tecnológicas ya no son un obstáculo, y los mapas sin clasificar son factibles, aún hay buenas razones para adoptar un enfoque clasificado. La principal de ellas es reducir la carga cognitiva que implica analizar la complejidad de un mapa sin clasificar. Un mapa coroplético reduce esta complejidad al basarse en la teoría estadística y de visualización para proporcionar una representación efectiva de la distribución espacial de los valores de los atributos a través de las unidades areales.
La efectividad de un mapa coroplético dependerá de la elección del esquema de clasificación junto con la estrategia de color o simbolización adoptada. En términos generales, el esquema de clasificación define el número de clases, así como las reglas para la asignación, mientras que la simbolización debe transmitir información sobre la diferenciación de los valores a través de las clases.
En este capítulo primero discutimos los enfoques utilizados para clasificar los valores de los atributos. Esto es seguido por una visión general de la teoría del color y las implicaciones de los diferentes esquemas de color para un diseño de mapas efectivo. Combinamos teoría y práctica al explorar cómo se implementan estos conceptos en diferentes paquetes de Python, incluyendo geopandas y PySAL.
En esta sesión, construiremos sobre todo lo que hemos aprendido hasta ahora sobre la carga y manipulación de datos (espaciales) y lo aplicaremos a una de las formas más comúnmente utilizadas de análisis espacial: los coropletas. Recuerden que estos son mapas que muestran la distribución espacial de una variable codificada en un esquema de colores, también llamado paleta. Aunque existen muchas formas de convertir los valores de una variable en un color específico, en este contexto nos centraremos solo en algunas de ellas, en particular:
Valores únicos
Intervalo igual
Cuantiles
Fisher-Jenks
Objetivos de aprendizaje#
Al finalizar este notebook, el estudiante será capaz de:
Comprender los principios teóricos de los mapas coropléticos y la importancia de la clasificación.
Aplicar distintos esquemas de clasificación disponibles en
mapclassify(cuantiles, Jenks, Head-Tail, Fisher-Jenks, etc.).Comparar clasificadores objetivamente usando el criterio ADCM (Absolute Deviation around Class Medians).
Seleccionar paletas de color apropiadas para variables secuenciales, divergentes y cualitativas.
Crear cartogramas como alternativa a los mapas coropléticos estándar.
Requisitos previos: 00_Data — GeoDataFrame de cuencas; 01_DatosEspaciales — mapas básicos con geopandas.
import seaborn as sbn
import geopandas as gpd
print(gpd.datasets.available)
['naturalearth_cities', 'naturalearth_lowres', 'nybb']
gdf = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
gdf.head();
C:\Users\edier\AppData\Local\Temp\ipykernel_25584\1466599543.py:1: FutureWarning: The geopandas.dataset module is deprecated and will be removed in GeoPandas 1.0. You can get the original 'naturalearth_lowres' data from https://www.naturalearthdata.com/downloads/110m-cultural-vectors/.
gdf = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
h = sbn.distplot(gdf['pop_est'], bins=5, rug=True);
C:\Users\edier\AppData\Local\Temp\ipykernel_25584\970683425.py:1: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
h = sbn.distplot(gdf['pop_est'], bins=5, rug=True);
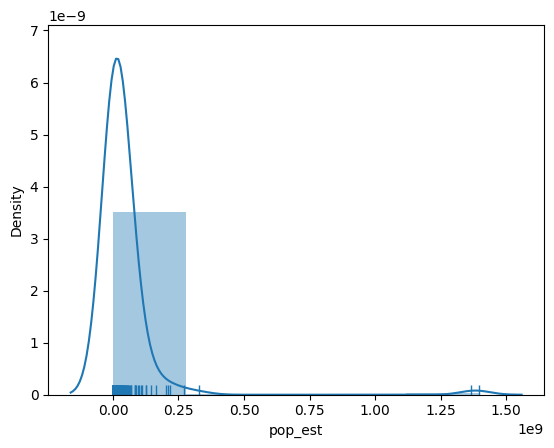
gdf['pop_est'].describe()
count 1.770000e+02
mean 4.324346e+07
std 1.513543e+08
min 1.400000e+02
25% 3.301000e+06
50% 1.019232e+07
75% 3.182530e+07
max 1.397715e+09
Name: pop_est, dtype: float64
Para atributos cuantitativos, primero ordenamos los datos por su valor, de modo que \(x₀ ≤ x₂ … ≤ xₙ₋₁\). Para un número preestablecido de clases k, el problema de clasificación se reduce a la selección de k−1 puntos de corte a lo largo de los valores ordenados que separan los valores en grupos mutuamente excluyentes y exhaustivos.
De hecho, la determinación del histograma anterior puede verse como un enfoque para esta selección. El método seaborn.distplot utiliza la función hist de matplotlib en segundo plano para determinar los límites de las clases y el conteo de observaciones en cada clase. En la figura, tenemos cinco clases que pueden extraerse con una llamada explícita a la función hist:
counts, bins, patches = h.hist(gdf['pop_est'], bins=5)
El objeto counts captura cuántas observaciones tiene cada categoría en la clasificación:
counts
array([174., 1., 0., 0., 2.])
The bin object stores these break points we are interested in when considering classification schemes (the patches object can be ignored in this context, as it stores the geometries of the histogram plot):
bins
array([1.40000000e+02, 2.79543112e+08, 5.59086084e+08, 8.38629056e+08,
1.11817203e+09, 1.39771500e+09])
Esto produce 5 clases, donde la primera tiene un límite inferior de 140 y un límite superior de 2.758e+08, que contiene 1 observación. La determinación del ancho del intervalo (\(w\)) y el número de clases en seaborn se basa en la regla de Freedman-Diaconis:
donde \(IQR\) es el rango intercuartílico de los valores del atributo. Dado \(w\), el número de clases (\(k\)) es:
A continuación, presentamos varios enfoques para crear estos puntos de corte que siguen criterios que pueden ser de interés en diferentes contextos, ya que se centran en diferentes prioridades.
Equal Intervals#
The Freedman-Diaconis approach provides a rule to determine the width and, in turn, the number of bins for the classification. This is a special case of a more general classifier known as “equal intervals”, where each of the bins has the same width in the value space. For a given value of \(k\), equal intervals classification splits the range of the attribute space into \(k\) equal length intervals, with each interval having a width \(w = \frac{x_0 - x_{n-1}}{k}\). Thus the maximum class is \((x_{n-1}-w, x_{n-1}]\) and the first class is \((-\infty, x_{n-1} - (k-1)w]\).
Equal intervals have the dual advantages of simplicity and ease of interpretation. However, this rule only considers the extreme values of the distribution and, in some cases, this can result in one or more classes being sparse. This is clearly the case in our income dataset, as the majority of the values are placed into the first two classes leaving the last three classes rather sparse:
import mapclassify
ei5 = mapclassify.EqualInterval(gdf['pop_est'], k=5)
ei5
EqualInterval
Interval Count
--------------------------------------
[ 140.00, 279543112.00] | 174
( 279543112.00, 559086084.00] | 1
( 559086084.00, 838629056.00] | 0
( 838629056.00, 1118172028.00] | 0
(1118172028.00, 1397715000.00] | 2
Cabe destacar que cada uno de los intervalos, sin embargo, tiene un ancho igual de \(w = 4093.8\). Este valor de \(k = 5\) también coincide con la clasificación predeterminada en el histograma de Seaborn mostrado en la Figura 1. También debe señalarse que la primera clase está cerrada en el límite inferior, en contraste con el enfoque general definido en la Ecuación (1).
Cuantiles#
Para evitar el posible problema de clases dispersas, se pueden utilizar los cuantiles de la distribución para identificar los límites de las clases. De hecho, cada clase tendrá aproximadamente \(\mid\frac{n}{k}\mid\) observaciones usando el clasificador de cuantiles. Si \(k=5\), se utilizan los quintiles de la muestra para definir los límites superiores de cada clase, lo que resulta en la siguiente clasificación:
q5 = mapclassify.Quantiles(gdf.pop_est, k=5)
q5
Quantiles
Interval Count
--------------------------------------
[ 140.00, 2527151.40] | 36
( 2527151.40, 6891417.80] | 35
( 6891417.80, 16156568.80] | 35
( 16156568.80, 39056177.20] | 35
( 39056177.20, 1397715000.00] | 36
Cabe señalar que, aunque el número de valores en cada clase es aproximadamente igual, los anchos de los primeros cuatro intervalos son bastante diferentes:
q5.bins[1:]-q5.bins[:-1]
array([4.36426640e+06, 9.26515100e+06, 2.28996084e+07, 1.35865882e+09])
Aunque los cuantiles evitan el problema de clases escasas, esta clasificación no está exenta de problemas. Los anchos variables de los intervalos pueden ser marcadamente diferentes, lo que puede llevar a problemas de interpretación. Un segundo desafío que enfrentan los cuantiles surge cuando hay un gran número de valores duplicados en la distribución, lo que puede hacer que los límites de una o más clases se vuelvan ambiguos. Por ejemplo, si se tiene una variable con \(n=20\) pero 10 de las observaciones toman el mismo valor, que además es el mínimo observado, entonces para valores de \(k>2\), los límites de las clases se vuelven mal definidos, ya que una simple regla de división en el valor observado de rango \(n/k\) dependería de cómo se traten los empates al clasificar.
Media-desviación estándar#
Nuestro tercer clasificador utiliza la media muestral \(\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i\) y la desviación estándar muestral \(s = \sqrt{ \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x}) }\) para definir los límites de las clases como una distancia desde la media muestral, siendo esta distancia un múltiplo de la desviación estándar. Por ejemplo, una definición común para \(k=5\) es fijar el límite superior de la primera clase a dos desviaciones estándar (\(c_{0}^u = \bar{x} - 2 s\)), y que las clases intermedias tengan límites superiores dentro de una desviación estándar (\(c_{1}^u = \bar{x}-s,\ c_{2}^u = \bar{x}+s, \ c_{3}^u = \bar{x}+2s\)). Cualquier valor mayor (o menor) que dos desviaciones estándar por encima (o por debajo) de la media se colocará en la clase superior (o inferior).
msd = mapclassify.StdMean(gdf['pop_est'])
msd
StdMean
Interval Count
--------------------------------------
( -inf, -259465120.56] | 0
(-259465120.56, -108110831.41] | 0
(-108110831.41, 194597746.90] | 170
( 194597746.90, 345952036.06] | 5
( 345952036.06, 1397715000.00] | 2
Este clasificador es mejor utilizado cuando los datos se distribuyen de manera normal o, al menos, cuando la media muestral es una medida significativa para anclar la clasificación. Claramente, este no es el caso para nuestros datos de ingresos, ya que la asimetría positiva resulta en una pérdida de información cuando utilizamos la desviación estándar. La falta de simetría lleva a un límite superior inadmisible para la primera clase, así como a una concentración de la gran mayoría de los valores en la clase media.
Máximas Rupturas (Natural break)#
El clasificador de máximas rupturas decide dónde establecer los puntos de corte entre las clases considerando la diferencia entre los valores ordenados. Es decir, en lugar de considerar un valor del conjunto de datos por sí mismo, analiza cuán separados están entre sí cada valor y el siguiente en la secuencia ordenada. El clasificador luego coloca los \(k-1\) puntos de corte entre los pares de valores más alejados entre sí en toda la secuencia, procediendo en orden descendente en relación con el tamaño de las rupturas:
mb5 = mapclassify.MaximumBreaks(gdf['pop_est'], k=5)
mb5
MaximumBreaks
Interval Count
--------------------------------------
[ 140.00, 182004880.00] | 170
( 182004880.00, 243595443.00] | 3
( 243595443.00, 299432545.50] | 1
( 299432545.50, 847328638.50] | 1
( 847328638.50, 1397715000.00] | 2
Las máximas rupturas son un enfoque apropiado cuando estamos interesados en asegurarnos de que las observaciones en cada clase estén separadas de aquellas en las clases vecinas. Por lo tanto, funciona bien en casos donde la distribución de los valores no es unimodal. Además, el algoritmo es relativamente rápido de calcular. Sin embargo, su simplicidad puede causar a veces resultados inesperados. En la medida en que solo considera las \(k-1\) diferencias más grandes entre valores consecutivos, otras diferencias y disimilitudes más matizadas dentro de los grupos pueden ser ignoradas.
Box-Plot#
La clasificación mediante diagrama de caja (box-plot) es una combinación de los clasificadores de cuantiles y de desviación estándar. Aquí \(k\) se predefine a seis, con el límite superior de la clase 0 fijado en \(q_{0.25}-h \, IQR\). \(IQR = q_{0.75}-q_{0.25}\) es el rango intercuartílico; \(h\) corresponde al multiplicador del \(IQR\) para obtener los límites de los bigotes (whiskers). El límite inferior de la sexta clase se fija en \(q_{0.75}+h \, IQR\). Las clases intermedias tienen sus límites superiores fijados en los percentiles 0.25, 0.50 y 0.75 de los valores del atributo.
bp = mapclassify.BoxPlot(gdf['pop_est'])
bp
BoxPlot
Interval Count
--------------------------------------
( -inf, -39485442.50] | 0
( -39485442.50, 3301000.00] | 45
( 3301000.00, 10192317.30] | 44
( 10192317.30, 31825295.00] | 44
( 31825295.00, 74611737.50] | 25
( 74611737.50, 1397715000.00] | 19
Cualquier valor que caiga en una de las clases extremas se define como un valor atípico (outlier). Cabe destacar que, dado que los valores de ingresos son no negativos por definición, la clase de outliers inferiores tiene un límite superior inadmisible, lo que significa que no sería posible tener valores atípicos inferiores en esta muestra.
El valor predeterminado para el multiplicador \(h\) es \(h=1.5\) en PySAL. Sin embargo, esto puede ser especificado por el usuario para una clasificación alternativa:
bp1 = mapclassify.BoxPlot(gdf['pop_est'], hinge=1)
bp1
BoxPlot
Interval Count
--------------------------------------
( -inf, -25223295.00] | 0
( -25223295.00, 3301000.00] | 45
( 3301000.00, 10192317.30] | 44
( 10192317.30, 31825295.00] | 44
( 31825295.00, 60349590.00] | 22
( 60349590.00, 1397715000.00] | 22
Hacer esto afectará la definición de las clases de outliers, así como las clases internas vecinas.
Head-Tail Breaks#
El algoritmo de Head-Tail [] se basa en una partición recursiva de los datos utilizando divisiones alrededor de medias iterativas. El proceso de división continúa hasta que las distribuciones dentro de cada clase ya no muestran una distribución de cola pesada, en el sentido de que hay un equilibrio entre el número de valores menores y mayores asignados a cada clase.
ht = mapclassify.HeadTailBreaks(gdf['pop_est'])
ht
HeadTailBreaks
Interval Count
--------------------------------------
[ 140.00, 43243457.75] | 144
( 43243457.75, 184117213.18] | 26
( 184117213.18, 570225184.14] | 5
( 570225184.14, 1382066377.00] | 1
(1382066377.00, 1397715000.00] | 1
Para datos con una distribución de cola pesada, como las distribuciones de ley de potencias y log-normal, el clasificador de Head-Tail Breaks puede ser particularmente efectivo.
Jenks Caspall#
Este enfoque, al igual que los dos siguientes, aborda el desafío de la clasificación desde una perspectiva heurística, en lugar de una determinista. Originalmente propuesto por [], este algoritmo tiene como objetivo minimizar la suma de las desviaciones absolutas alrededor de las medias de las clases. El enfoque comienza con un número preestablecido de clases y un conjunto inicial arbitrario de puntos de corte, por ejemplo, utilizando quintiles. El algoritmo intenta mejorar la función objetivo considerando el movimiento de observaciones entre clases adyacentes. Por ejemplo, se consideraría mover el valor más alto del quintil inferior al segundo quintil, mientras que el valor más bajo del segundo quintil se consideraría para un posible movimiento al primer quintil. El movimiento candidato que resultara en la mayor reducción de la función objetivo se realizaría, y el proceso continúa hasta que no sean posibles más movimientos que mejoren el resultado.
jc5 = mapclassify.JenksCaspall(gdf['pop_est'], k=5)
jc5
JenksCaspall
Interval Count
--------------------------------------
[ 140.00, 3301000.00] | 45
( 3301000.00, 8082366.00] | 32
( 8082366.00, 23568378.00] | 45
( 23568378.00, 69625582.00] | 36
( 69625582.00, 1397715000.00] | 19
Fisher Jenks#
El segundo algoritmo óptimo adopta un enfoque de programación dinámica para minimizar la suma de las desviaciones absolutas alrededor de las medianas de las clases. A diferencia del enfoque Jenks-Caspall, Fisher-Jenks garantiza producir una clasificación óptima para un número preestablecido de clases:
Max-p#
Finalmente, los clasificadores Max-p adoptan el algoritmo subyacente al método de construcción de regiones max-p [] para el caso de la clasificación de mapas. Es similar en espíritu a Jenks-Caspall en el sentido de que considera intercambios voraces entre clases adyacentes para mejorar la función objetivo. Sin embargo, es un enfoque heurístico, por lo que, a diferencia de Fisher-Jenks, no se garantiza una solución óptima:
mp5 = mapclassify.MaxP(gdf['pop_est'], k=5)
mp5
MaxP
Interval Count
--------------------------------------
[ 140.00, 2172579.00] | 33
( 2172579.00, 12771246.00] | 71
( 12771246.00, 16296364.00] | 3
( 16296364.00, 39309783.00] | 35
( 39309783.00, 1397715000.00] | 35
Comparación de esquemas de clasificación#
Como un caso especial de agrupamiento, la definición del número de clases y los límites de las clases plantea un problema para el diseñador de mapas. Recordemos que se dijo que la regla de Freedman-Diaconis era óptima; sin embargo, dicha optimalidad requiere la especificación de una función objetivo. En el caso de Freedman-Diaconis, la función objetivo es minimizar la diferencia entre el área bajo la densidad estimada del kernel basada en la muestra y el área bajo la distribución poblacional teórica que generó la muestra.
Esta noción de ajuste estadístico es importante. Sin embargo, no es la única consideración al evaluar clasificadores para el propósito de mapas coropléticos. También es relevante la distribución espacial de los valores del atributo y la capacidad del clasificador para transmitir una idea de esa distribución espacial. Como veremos, esto no está necesariamente relacionado directamente con la distribución estadística de los valores del atributo. Volveremos a una consideración conjunta tanto de la distribución estadística como espacial de los valores del atributo en la comparación de clasificadores a continuación.
Para la clasificación de mapas, un criterio de optimalidad que se puede utilizar es una medida de ajuste. En PySAL, se calcula la “desviación absoluta alrededor de las medianas de las clases” (ADCM) y proporciona una medida de ajuste que permite la comparación de clasificadores alternativos para el mismo valor de \(k\).
Para ver esto, podemos comparar diferentes clasificadores para \(k=5\) en los datos de México:
import numpy as np
import pandas as pd
import seaborn as sbn
class5 = q5, ei5, ht, mb5, msd, jc5
fits = np.array([ c.adcm for c in class5])
data = pd.DataFrame(fits)
data['classifier'] = [c.name for c in class5]
data.columns = ['ADCM', 'Classifier']
ax = sbn.barplot(y='Classifier', x='ADCM', data=data)
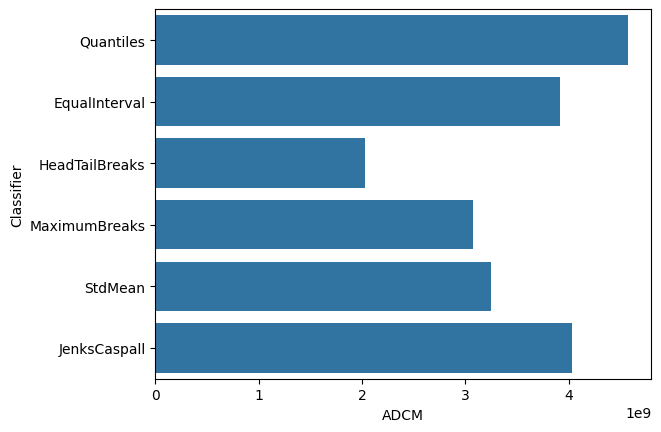
Como era de esperar, el clasificador Fisher-Jenks domina a todos los demás clasificadores con \(k=5\), con un ADCM de 23,729. Curiosamente, el clasificador de intervalo igual tiene un buen desempeño a pesar de los problemas asociados con su sensibilidad a los valores extremos en la distribución. El clasificador de media-desviación estándar tiene un ajuste muy pobre debido a la naturaleza sesgada de los datos y a la asignación concentrada de la mayoría de las observaciones en la clase central.
El ADCM proporciona una medida global de ajuste que puede ser utilizada para comparar los clasificadores alternativos. Como complemento de esta perspectiva global, puede ser revelador considerar cómo se clasificó cada una de las observaciones espaciales en los distintos enfoques. Para hacer esto, podemos añadir el atributo de clase (yb) generado por los clasificadores de PySAL como columnas adicionales en el marco de datos y presentarlas conjuntamente en una tabla:
gdf['q540'] = q5.yb
gdf['ei540'] = ei5.yb
gdf['ht40'] = ht.yb
gdf['mb540'] = mb5.yb
gdf['msd40'] = msd.yb
gdf['jc540'] = jc5.yb
gdfs = gdf.sort_values('pop_est')
def highlight_values(val):
if val==0:
return 'background-color: %s' % '#ffffff'
elif val==1:
return 'background-color: %s' % '#e0ffff'
elif val==2:
return 'background-color: %s' % '#b3ffff'
elif val==3:
return 'background-color: %s' % '#87ffff'
elif val==4:
return 'background-color: %s' % '#62e4ff'
else:
return ''
t = gdfs[['name', 'pop_est', 'q540', 'ei540', 'ht40', 'mb540', 'msd40', 'jc540']]
t.style.applymap(highlight_values)
| name | pop_est | q540 | ei540 | ht40 | mb540 | msd40 | jc540 | |
|---|---|---|---|---|---|---|---|---|
| 23 | Fr. S. Antarctic Lands | 140.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 20 | Falkland Is. | 3398.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 159 | Antarctica | 4490.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 22 | Greenland | 56225.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 134 | New Caledonia | 287800.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 89 | Vanuatu | 299882.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 160 | N. Cyprus | 326000.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 144 | Iceland | 361313.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 19 | Bahamas | 389482.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 39 | Belize | 390353.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 149 | Brunei | 433285.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 42 | Suriname | 581363.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 2 | W. Sahara | 603253.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 128 | Luxembourg | 619896.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 173 | Montenegro | 622137.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 135 | Solomon Is. | 669823.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 100 | Bhutan | 763092.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 41 | Guyana | 782766.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 0 | Fiji | 889953.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 166 | Djibouti | 973560.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 73 | eSwatini | 1148130.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 161 | Cyprus | 1198575.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 24 | Timor-Leste | 1293119.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 120 | Estonia | 1326590.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 69 | Eq. Guinea | 1355986.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 175 | Trinidad and Tobago | 1394973.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 174 | Kosovo | 1794248.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 119 | Latvia | 1912789.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 62 | Guinea-Bissau | 1920922.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 171 | North Macedonia | 2083459.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 150 | Slovenia | 2087946.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 26 | Lesotho | 2125268.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 68 | Gabon | 2172579.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 49 | Botswana | 2303697.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 80 | Gambia | 2347706.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 50 | Namibia | 2494530.000000 | 0 | 0 | 0 | 0 | 2 | 0 |
| 116 | Moldova | 2657637.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 118 | Lithuania | 2786844.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 85 | Qatar | 2832067.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 125 | Albania | 2854191.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 46 | Jamaica | 2948279.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 109 | Armenia | 2957731.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 45 | Puerto Rico | 3193694.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 97 | Mongolia | 3225167.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 170 | Bosnia and Herz. | 3301000.000000 | 1 | 0 | 0 | 0 | 2 | 0 |
| 28 | Uruguay | 3461734.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 146 | Georgia | 3720382.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 126 | Croatia | 4067500.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 86 | Kuwait | 4207083.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 33 | Panama | 4246439.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 53 | Mauritania | 4525696.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 79 | Palestine | 4685306.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 66 | Central African Rep. | 4745185.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 136 | New Zealand | 4917000.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 63 | Liberia | 4937374.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 133 | Ireland | 4941444.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 88 | Oman | 4974986.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 34 | Costa Rica | 5047561.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 167 | Somaliland | 5096159.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 21 | Norway | 5347896.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 67 | Congo | 5380508.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 152 | Slovakia | 5454073.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 151 | Finland | 5520314.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 142 | Denmark | 5818553.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 106 | Turkmenistan | 5942089.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 154 | Eritrea | 6081196.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 37 | El Salvador | 6453553.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 105 | Kyrgyzstan | 6456900.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 35 | Nicaragua | 6545502.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 164 | Libya | 6777452.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 77 | Lebanon | 6855713.000000 | 1 | 0 | 0 | 0 | 2 | 1 |
| 172 | Serbia | 6944975.000000 | 2 | 0 | 0 | 0 | 2 | 1 |
| 122 | Bulgaria | 6975761.000000 | 2 | 0 | 0 | 0 | 2 | 1 |
| 156 | Paraguay | 7044636.000000 | 2 | 0 | 0 | 0 | 2 | 1 |
| 92 | Laos | 7169455.000000 | 2 | 0 | 0 | 0 | 2 | 1 |
| 64 | Sierra Leone | 7813215.000000 | 2 | 0 | 0 | 0 | 2 | 1 |
| 58 | Togo | 8082366.000000 | 2 | 0 | 0 | 0 | 2 | 1 |
| 127 | Switzerland | 8574832.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 7 | Papua New Guinea | 8776109.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 114 | Austria | 8877067.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 76 | Israel | 9053300.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 104 | Tajikistan | 9321018.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 111 | Belarus | 9466856.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 36 | Honduras | 9746117.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 115 | Hungary | 9769949.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 84 | United Arab Emirates | 9770529.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 145 | Azerbaijan | 10023318.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 83 | Jordan | 10101694.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 12 | Somalia | 10192317.300000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 131 | Portugal | 10269417.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 110 | Sweden | 10285453.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 153 | Czechia | 10669709.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 123 | Greece | 10716322.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 17 | Dominican Rep. | 10738958.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 176 | S. Sudan | 11062113.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 16 | Haiti | 11263077.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 47 | Cuba | 11333483.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 129 | Belgium | 11484055.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 30 | Bolivia | 11513100.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 75 | Burundi | 11530580.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 81 | Tunisia | 11694719.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 54 | Benin | 11801151.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 169 | Rwanda | 12626950.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 61 | Guinea | 12771246.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 48 | Zimbabwe | 14645468.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 15 | Chad | 15946876.000000 | 2 | 0 | 0 | 0 | 2 | 2 |
| 51 | Senegal | 16296364.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 90 | Cambodia | 16486542.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 38 | Guatemala | 16604026.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 108 | Syria | 17070135.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 130 | Netherlands | 17332850.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 44 | Ecuador | 17373662.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 70 | Zambia | 17861030.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 5 | Kazakhstan | 18513930.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 71 | Malawi | 18628747.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 10 | Chile | 18952038.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 117 | Romania | 19356544.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 52 | Mali | 19658031.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 65 | Burkina Faso | 20321378.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 138 | Sri Lanka | 21803000.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 55 | Niger | 23310715.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 140 | Taiwan | 23568378.000000 | 3 | 0 | 0 | 0 | 2 | 2 |
| 137 | Australia | 25364307.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 95 | North Korea | 25666161.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 60 | Côte d'Ivoire | 25716544.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 57 | Cameroon | 25876380.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 78 | Madagascar | 26969307.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 40 | Venezuela | 28515829.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 101 | Nepal | 28608710.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 157 | Yemen | 29161922.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 72 | Mozambique | 30366036.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 59 | Ghana | 30417856.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 74 | Angola | 31825295.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 148 | Malaysia | 31949777.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 31 | Peru | 32510453.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 6 | Uzbekistan | 33580650.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 158 | Saudi Arabia | 34268528.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 162 | Morocco | 36471769.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 3 | Canada | 37589262.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 113 | Poland | 37970874.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 103 | Afghanistan | 38041754.000000 | 3 | 0 | 0 | 0 | 2 | 3 |
| 87 | Iraq | 39309783.000000 | 4 | 0 | 0 | 0 | 2 | 3 |
| 14 | Sudan | 42813238.000000 | 4 | 0 | 0 | 0 | 2 | 3 |
| 82 | Algeria | 43053054.000000 | 4 | 0 | 0 | 0 | 2 | 3 |
| 168 | Uganda | 44269594.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 112 | Ukraine | 44385155.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 9 | Argentina | 44938712.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 132 | Spain | 47076781.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 32 | Colombia | 50339443.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 96 | South Korea | 51709098.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 13 | Kenya | 52573973.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 93 | Myanmar | 54045420.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 1 | Tanzania | 58005463.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 25 | South Africa | 58558270.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 141 | Italy | 60297396.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 143 | United Kingdom | 66834405.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 43 | France | 67059887.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 91 | Thailand | 69625582.000000 | 4 | 0 | 1 | 0 | 2 | 3 |
| 107 | Iran | 82913906.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 121 | Germany | 83132799.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 124 | Turkey | 83429615.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 11 | Dem. Rep. Congo | 86790567.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 94 | Vietnam | 96462106.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 163 | Egypt | 100388073.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 147 | Philippines | 108116615.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 165 | Ethiopia | 112078730.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 155 | Japan | 126264931.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 27 | Mexico | 127575529.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 18 | Russia | 144373535.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 99 | Bangladesh | 163046161.000000 | 4 | 0 | 1 | 0 | 2 | 4 |
| 56 | Nigeria | 200963599.000000 | 4 | 0 | 2 | 1 | 3 | 4 |
| 29 | Brazil | 211049527.000000 | 4 | 0 | 2 | 1 | 3 | 4 |
| 102 | Pakistan | 216565318.000000 | 4 | 0 | 2 | 1 | 3 | 4 |
| 8 | Indonesia | 270625568.000000 | 4 | 0 | 2 | 2 | 3 | 4 |
| 4 | United States of America | 328239523.000000 | 4 | 1 | 2 | 3 | 3 | 4 |
| 98 | India | 1366417754.000000 | 4 | 4 | 3 | 4 | 4 | 4 |
| 139 | China | 1397715000.000000 | 4 | 4 | 4 | 4 | 4 | 4 |
La inspección de esta tabla revela una serie de resultados interesantes. Primero, la única ciudad que es tratada de manera consistente en todos los clasificadores con \(k=5\) es China, que es colocada en la clase más alta por todos los clasificadores.
Finalmente, podemos considerar una vista a nivel meso de los resultados de la clasificación comparando el número de valores asignados a cada clase en los diferentes clasificadores:
pd.DataFrame({c.name: c.counts for c in class5},index=['Class-{}'.format(i) for i in range(5)])
| Quantiles | EqualInterval | HeadTailBreaks | MaximumBreaks | StdMean | JenksCaspall | |
|---|---|---|---|---|---|---|
| Class-0 | 36 | 174 | 144 | 170 | 0 | 45 |
| Class-1 | 35 | 1 | 26 | 3 | 0 | 32 |
| Class-2 | 35 | 0 | 5 | 1 | 170 | 45 |
| Class-3 | 35 | 0 | 1 | 1 | 5 | 36 |
| Class-4 | 36 | 2 | 1 | 2 | 2 | 19 |
Al hacerlo, se destacan las similitudes entre Fisher Jenks e intervalos iguales, ya que los conteos de distribución son muy similares y ambos enfoques coinciden en los 17 estados asignados a la primera clase. De hecho, la única observación que distingue a los dos clasificadores es el tratamiento de Baja California Sur, que se mantiene en la clase 1 en intervalos iguales, pero es asignada a la clase 2 por Fisher Jenks.
import matplotlib.pyplot as plt
f, ax = plt.subplots(1, figsize=(12,7))
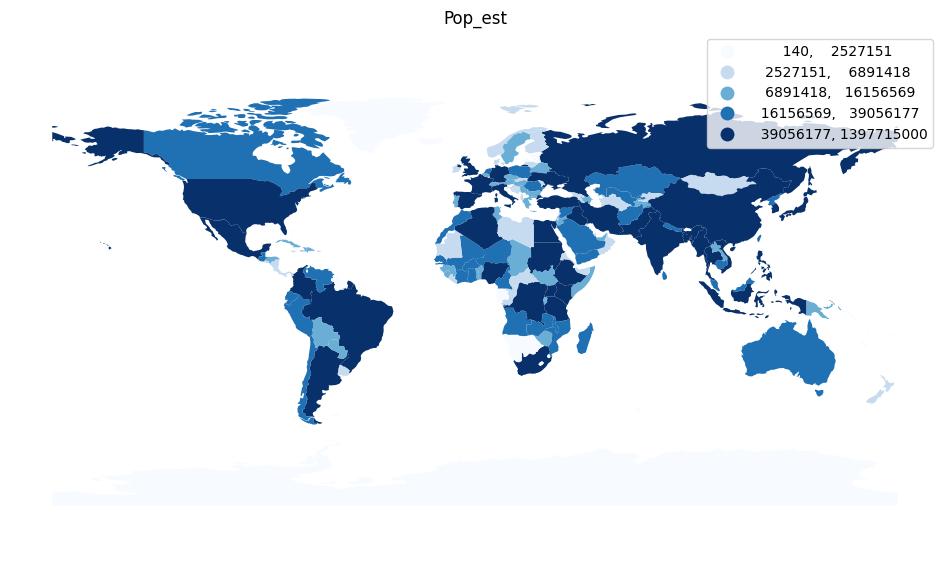
gdf.plot(ax=ax, column='pop_est', legend=True, scheme='Quantiles', legend_kwds={'fmt':'{:.0f}'}, \
cmap='Blues')
ax.set_axis_off()
ax.set_title('Pop_est')
plt.axis('equal')
plt.show()
Cartogramas#
Los cartogramas son mapas que representan la distribución espacial de una variable no mediante su codificación en una paleta de colores, sino modificando los objetos geográficos. Existen muchos algoritmos para distorsionar las formas de las entidades geográficas de acuerdo con los valores, algunos de ellos increíblemente complicados y complejos.
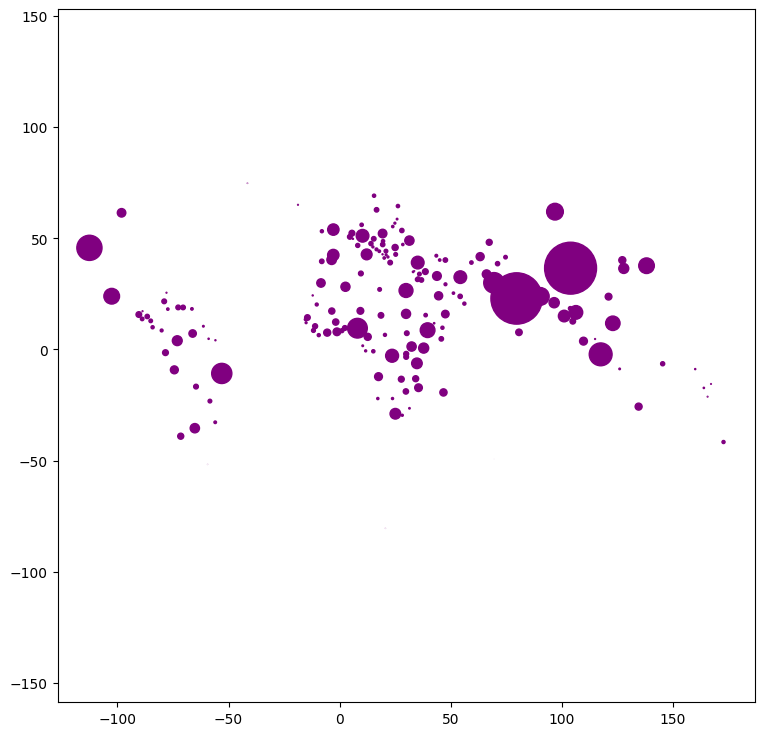
Como ejemplo de cómo crear un cartograma relativamente simple, convertiremos polígonos en puntos usando sus centroides y definiremos el tamaño del punto proporcionalmente al valor de la variable que queremos mostrar, el puntaje IMD en este caso. Adoptaremos un enfoque diferente para graficar los puntos en comparación con lo que hemos hecho hasta ahora. Esto implica primero extraer las coordenadas de los puntos:
pts = np.array([(pt.x, pt.y) for pt in gdf.centroid])
pts = []
for pt in gdf.centroid:
pts.append((pt.x, pt.y))
pts = np.array(pts)
C:\Users\edier\AppData\Local\Temp\ipykernel_25584\3724468419.py:1: UserWarning: Geometry is in a geographic CRS. Results from 'centroid' are likely incorrect. Use 'GeoSeries.to_crs()' to re-project geometries to a projected CRS before this operation.
pts = np.array([(pt.x, pt.y) for pt in gdf.centroid])
C:\Users\edier\AppData\Local\Temp\ipykernel_25584\3724468419.py:4: UserWarning: Geometry is in a geographic CRS. Results from 'centroid' are likely incorrect. Use 'GeoSeries.to_crs()' to re-project geometries to a projected CRS before this operation.
for pt in gdf.centroid:
Una vez que los hayamos extraído, podemos mostrarlos mediante el comando plt.scatter. Esto es equivalente a un simple plot, o a un bucle sobre cada punto, con la diferencia de que nos permitirá modificar el tamaño de los puntos de acuerdo con una variable:
Una vez que los hayamos extraído, podemos mostrarlos mediante el comando plt.scatter. Esto es equivalente a un simple plot, o a un bucle sobre cada punto, con la diferencia de que nos permitirá modificar el tamaño de los puntos de acuerdo con una variable:
# Set up figure and axes
f, ax = plt.subplots(1, figsize=(9, 9))
# Plot the dots, using `imd_score` as a variable to modify
# the size of each dot
ax.scatter(pts[:, 0], pts[:, 1], c='purple', s=gdf['pop_est'].values/1000000)
# Keep axes proportionate
ax.axis("equal")
# Display
plt.show()
Ejemplo can datos de cuencas#
import geopandas as gpd
#gdf = gpd.read_file("https://github.com/edieraristizabal/ModeloMultinivel/raw/refs/heads/main/DATA/df_catchments_spatial.gpkg")
#gdf.info()
import requests
from io import BytesIO
url = "https://github.com/edieraristizabal/ModeloMultinivel/raw/refs/heads/main/DATA/df_catchments_spatial.gpkg"
try:
response = requests.get(url, stream=True)
response.raise_for_status() # Lanza una excepción para errores HTTP
# Lee el contenido descargado como un archivo en memoria
with BytesIO(response.content) as f:
gdf = gpd.read_file(f)
except requests.exceptions.RequestException as e:
print(f"Error al descargar el archivo: {e}")
except Exception as e:
print(f"Error al leer el archivo GPKG: {e}")
f, ax = plt.subplots(1, figsize=(10,7))
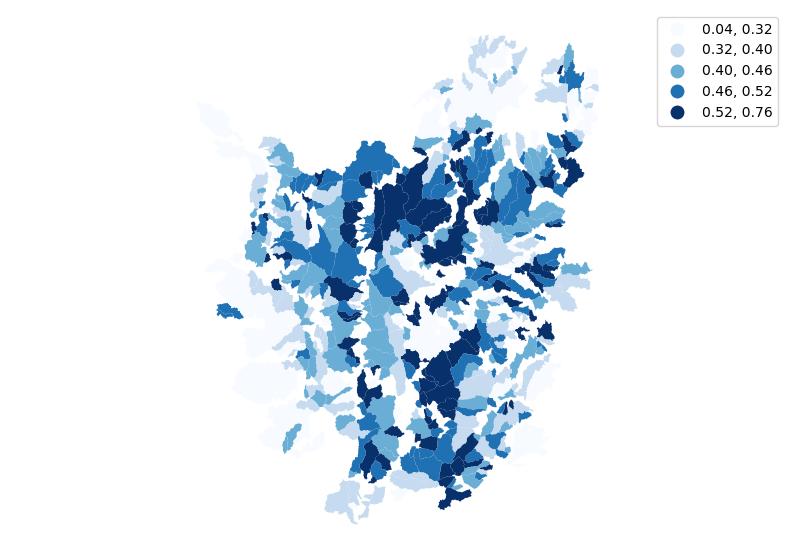
gdf.plot(ax=ax, column='hypso_inte', legend=True, scheme='Quantiles', legend_kwds={'fmt':'{:.2f}'}, cmap='Blues')
ax.set_axis_off()
plt.axis('equal')
plt.show()
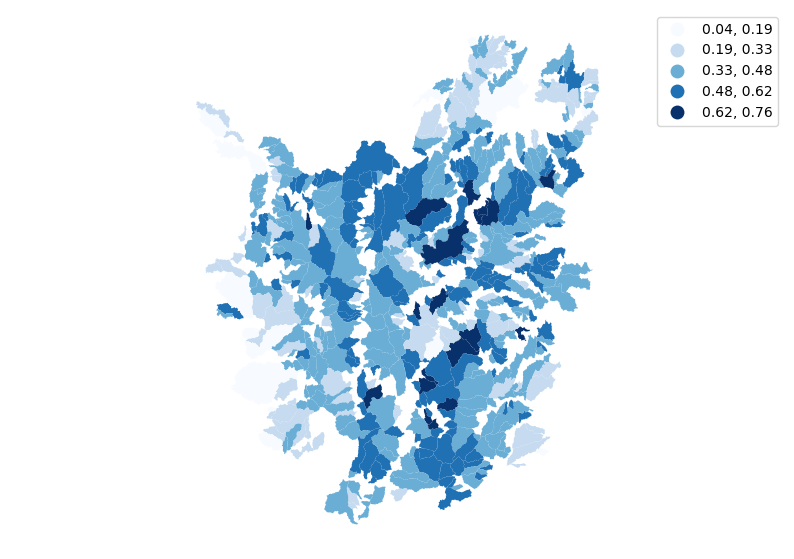
f, ax = plt.subplots(1, figsize=(10,7))
gdf.plot(ax=ax, column='hypso_inte', legend=True, scheme='EqualInterval', legend_kwds={'fmt':'{:.2f}'}, cmap='Blues')
ax.set_axis_off()
plt.axis('equal')
plt.show()
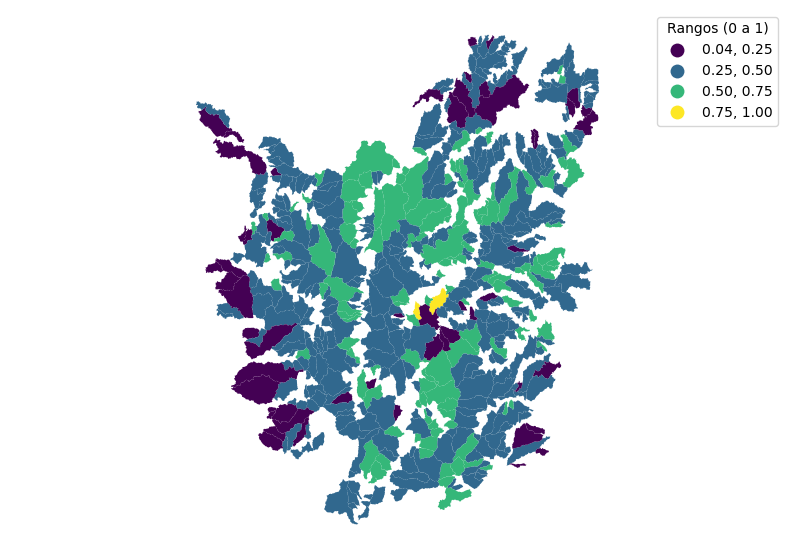
# Definir los 4 rangos (los valores son los límites superiores de cada rango)
bins = [0.25, 0.5, 0.75, 1.0]
f, ax = plt.subplots(1, figsize=(10, 7))
gdf.plot(ax=ax,
column='hypso_inte',
legend=True,
scheme='UserDefined',
classification_kwds={'bins': bins},
cmap='viridis',
legend_kwds={'title': 'Rangos (0 a 1)'})
ax.set_axis_off()
plt.axis('equal')
plt.show()
Actividades#
Comparación de clasificadores: Para la variable
lands_recdel dataset de cuencas, aplica al menos 5 esquemas de clasificación distintos disponibles enmapclassify(p.ej. Cuantiles, Jenks, Equal Intervals, Head-Tail, BoxPlot). Para cada uno, reporta el valor de ADCM (Absolute Deviation around Class Medians). ¿Cuál produce la clasificación más precisa?Elección del número de clases: Para el clasificador Fisher-Jenks, crea mapas con 3, 5 y 7 clases de la densidad de deslizamientos. Evalúa cuál comunicaría mejor el patrón espacial a una audiencia no técnica. Argumenta considerando la legibilidad visual y la precisión estadística.
Escala de color: Para un mapa coropléto de pendiente media (
slope_mean), prueba tres paletas de colores distintas: (a) secuencial (e.g.YlOrRd), (b) divergente (e.g.RdBu) y (c) cualitativa. ¿Cuál es más apropiada para esta variable y por qué?Cartograma: Usando la librería
geopandasocartopy, crea un cartograma donde el tamaño de cada subcuenca es proporcional a su número de deslizamientos. Compara visualmente con el mapa coropléto estándar: ¿qué patrón espacial queda más claro en cada tipo de mapa?
Recursos adicionales#
Documentación oficial#
Lecturas recomendadas#
Jenks, G. F. & Caspall, F. C. (1971). Error on choroplethic maps: Definition, measurement, reduction. Annals of the AAG, 61(2), 217–244.
MacEachren, A. M. (1994). Some Truth with Maps: A Primer on Symbolization and Design. AAG.
Monmonier, M. (1991). How to Lie with Maps. University of Chicago Press.
Head, C. G. & Tail, C. (1993). Head/tail breaks: A new classification scheme for data with a heavy-tailed distribution. The Professional Geographer, 65(3), 482–494.