Créditos: El contenido de este cuaderno ha sido tomado de varias fuentes, pero especialmente de Dani Arribas-Bel - University of Liverpool & Sergio Rey - Center for Geospatial Sciences, University of California, Riverside. El compilador se disculpa por cualquier omisión involuntaria y estaría encantado de agregar un reconocimiento.
Ambiente computacional#
El curso se basa principalmente en el lenguaje de programación Python y R. Python y R son lenguajes de programación de alto nivel ampliamente utilizados en la actualidad. Ser un lenguaje de alto nivel significa que el código puede ser “interpretado dinámicamente”, lo que significa que se ejecuta sobre la marcha sin necesidad de compilarlo. Esto contrasta con los lenguajes de programación “de bajo nivel”, que primero deben convertirse en código máquina (es decir, compilados) antes de que puedan ejecutarse. Con Python y R, no necesitas preocuparte por la compilación y puedes simplemente escribir código, evaluarlo, corregirlo, volver a evaluarlo, etc., en un ciclo rápido, lo que lo convierte en una herramienta muy productiva.
Python es un lenguaje extremadamente útil para aprender en términos de SIG (Sistemas de Información Geográfica), ya que muchos (o la mayoría) de los diferentes paquetes de software SIG (como ArcGIS, QGIS, PostGIS, etc.) proporcionan una interfaz para hacer análisis usando scripts en Python. Durante este curso, nos centraremos principalmente en hacer análisis geoespaciales sin ningún software de terceros, como ArcGIS y QGIS.
En el mundo geoespacial, Python también ha sido ampliamente adoptado, siendo el lenguaje seleccionado para scripting en ambos, ArcGIS y QGIS. Sin embargo desde el punto de vista netamente estadístico R tiene todavia ventajas. Existen librerías estadísticas mas sofisticadas en R que aun no han sido desarrolladas en Python.
Objetivos de aprendizaje#
Al finalizar este notebook, el estudiante será capaz de:
Configurar un entorno de trabajo reproducible para análisis geoespacial con Python y R.
Comprender las diferencias entre gestores de paquetes (
conda,pip) y cuándo usar cada uno.Crear y activar entornos virtuales con Conda para aislar dependencias de proyectos.
Utilizar Jupyter Lab como entorno interactivo de desarrollo (concepto REPL, kernels, celdas).
Inicializar un repositorio Git y gestionar el control de versiones de un proyecto geoespacial.
Autenticarse y ejecutar scripts básicos en Google Earth Engine (GEE) desde Python.
Requisitos previos: Ninguno — este es el primer capítulo del libro.
Control de Versiones: Git y GitHub#
En el marco de la investigación científica contemporánea, la gestión de scripts de análisis, modelos numéricos y flujos de trabajo geoespaciales exige un sistema que garantice la trazabilidad y reproducibilidad. El uso de sistemas de control de versiones (VCS) permite documentar la evolución de un proyecto, facilitando la auditoría de procesos y la colaboración multidisciplinar.
Git: Es un motor de control de versiones distribuido de código abierto Git. Su función es realizar un seguimiento exhaustivo de las modificaciones en archivos de texto (como scripts de R, Python o archivos LaTeX), permitiendo revertir cambios, crear ramas de experimentación y gestionar el historial de una investigación.
GitHub: Es una plataforma Github de alojamiento basada en la nube que integra la funcionalidad de Git. Proporciona una interfaz para la gestión de proyectos, revisión de código y colaboración remota entre investigadores.
Git#
En el flujo de trabajo de Git, el concepto de “carpeta” se gestiona mediante la inicialización de un repositorio. No se crean carpetas desde Git, sino que se transforman directorios existentes en unidades bajo seguimiento.
Inicialización del Proyecto#
Para convertir un directorio de trabajo en un repositorio bajo control de versiones:
# Creación del directorio de trabajo en el sistema operativo
mkdir analisis_riesgo_geologico
cd analisis_riesgo_geologico
# Inicialización del repositorio Git
git init
Registro de Cambios (Commits)#
Un commit representa un estado inmutable en el historial del proyecto. Es fundamental que cada registro posea un mensaje atómico y descriptivo del cambio realizado para asegurar la trazabilidad.
# Creación de un script de procesamiento espacial de ejemplo
echo "import geopandas as gpd" > procesamiento_hidrologico.py
# 1. Adición del archivo al área de preparación (Staging Area)
git add procesamiento_hidrologico.py
# 2. Consolidación del cambio en el historial local
git commit -m "Implementación inicial de la carga de geometrías vectoriales"
GitHub#
Para trabajar con proyectos alojados en la nube, se utilizan mecanismos de descarga y vinculación remota.
# Clonación de un repositorio remoto existente a la máquina local
git clone [https://github.com/institucion/proyecto-landslides.git](https://github.com/institucion/proyecto-landslides.git)
# Envío de versiones locales al servidor remoto (Sincronización ascendente)
git push origin main
El comando git pull es una combinación de dos procesos: descargar los cambios del servidor (fetch) e integrarlos en el código local (merge).
# Recuperación e integración de contribuciones externas
git pull origin main
Gestión de Conflictos y Sincronización#
La ejecución de un git pull es obligatoria en dos escenarios: (i) Al iniciar una jornada de trabajo, para asegurar que se opera sobre la versión más reciente del proyecto. (ii) Antes de realizar un git push, si el repositorio remoto contiene cambios que no existen en la base local.
Un conflicto ocurre cuando el sistema detecta ediciones concurrentes e incompatibles en la misma sección de un archivo. Git detiene el proceso de integración para que el investigador determine la validez técnica de los cambios.
Detección: Git notificará el conflicto en la terminal indicando los archivos afectados.
Intervención: El usuario debe abrir el archivo y resolver la discrepancia manualmente entre los marcadores:
<<<<<<< HEAD
# Algoritmo de interpolación Kriging optimizado
=======
# Algoritmo de interpolación IDW para pruebas rápidas
>>>>>>> 1a2b3c4d...
Consolidación: Una vez resuelta la ambigüedad, se debe marcar el archivo como solucionado y registrar el nuevo estado:
git add procesamiento_hidrologico.py
git commit -m "Resolución de conflicto: Integración de algoritmos de interpolación"
git push origin main
Conda#
Las dos distribuciones más populares de Python son Anaconda y Miniconda, que son compatibles con R. Anaconda es una distribución de Python de código abierto diseñada específicamente para la ciencia de datos, el aprendizaje automático y el procesamiento de datos a gran escala. Incluye el lenguaje Python y R, más de 1,500 paquetes de ciencia de datos, un sistema de gestión de paquetes llamado conda, IPython (un intérprete interactivo de Python) y mucho más. Si bien es una distribución muy completa, también es bastante grande y, por lo tanto, puede tardar un tiempo en descargarse y consumir mucho espacio en disco. Miniconda, por otro lado, es una versión reducida de Anaconda e incluye todos los mismos componentes excepto los 1,500 paquetes de ciencia de datos pre-instalados. En su lugar, podemos simplemente instalar estos paquetes individualmente según sea necesario utilizando Conda (el gestor de paquetes de Anaconda/Miniconda). Tal vez la mayor diferencia es que Miniconda no tiene una interfaz de usuario como Anaconda, debe ser a través de la línea de comando.
Elige Anaconda si:
Eres nuevo en conda o Python.
Te gusta la conveniencia de tener Python y más de 1,500 paquetes científicos instalados automáticamente de una vez.
Tienes tiempo y espacio en disco.
No deseas instalar individualmente cada uno de los paquetes que deseas usar.
Elige Miniconda si:
Tienes conocimientos en programación.
No te importa instalar individualmente los paquetes que deseas usar.
No tienes tiempo o espacio en disco para instalar más de 1,500 paquetes de una vez.
Quieres un acceso rápido a Python y los comandos conda, y deseas resolver el resto de los programas más tarde.

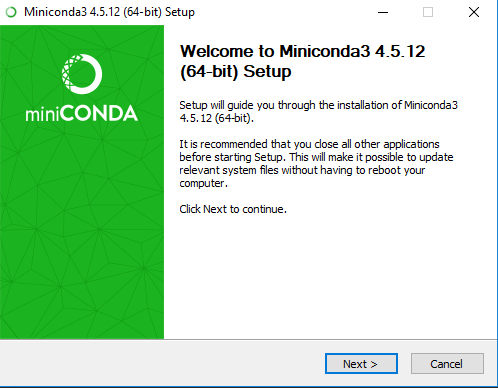
Ten en cuenta que el instalador te preguntará si deseas hacer dos cosas:
Agregar “Anaconda” a la variable de entorno “PATH”. Aunque en el texto del instalador dice que no lo hagas, te recomiendo que lo marques. Si no lo haces, cuando digites Python en la línea de comando, el sistema no reconocerá la orden ya que no encuentra la ruta de Python. Por lo tanto deberá manualmente incluir en las variables de entrono la ruta donde se encuentra Conda.
Registrar “Anaconda” como mi “Python 3.7 predeterminado”. Esto viene marcado por defecto y lo recomiendan.
Si prefieres instalar Python sin Anaconda o Miniconda, ve a la página de Python y descarga el instalador ejecutable de la última versión estable. Una vez completada la descarga, ejecuta el instalador. En la primera página del instalador, asegúrate de seleccionar la opción “Agregar Python al PATH” y haz click en los pasos de instalación restantes dejando todas las opciones predeterminadas preseleccionadas.

PIP#
Para trabajar con Python o R debes utilizar librerías. Las cuales ofrecen paquetes de funciones que procesan los datos o análisis que queremos ejecutar. Para instalar librerías se utiliza Conda o pip. Pip es un gestor de librerías diseñado específicamente para instalar paquetes de Python exclusivamente. La diferencia con Conda, es que PIP es exclusivo para Python.
Si trabaja en un ambiente Conda se recomienda utilizar dicho gestor de librerías, sin embargo existen librerías que no están disponibles en Conda, lo cual requiere que se instalen con PIP. El cambio de gestor de librerías puede generar en algunas ocasiones incompatibilidades entre las librerías.
Es por esta razon que es común, tanto con Python como R, trabajar dentro de entornos o ambientes virtuales.
Ambiente virtual y librerias#
Se recomienda crear un entorno para el análisis espacial. Los entornos pueden considerarse repositorios en los que se instalan paquetes de Python para evitar conflictos entre paquetes y versiones. Por ejemplo, si tienes un código desarrollado utilizando la versión 1.18 de NumPy y este código no funciona con la versión actual que es 1.20, puedes (y deberías) crear entornos específicos para cada versión. Conda viene inicialmente con un entorno estándar llamado base (root). Se recomienda mantener este entorno sin modificar.
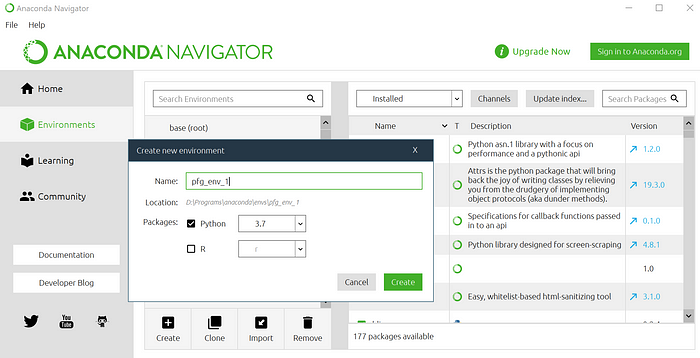
En Anaconda se crea un entorno haciendo clic en la pestaña Entornos (Environments) a la izquierda y en el botón Crear (Create) debajo de la lista de entornos. A este nuevo entorno le podemos dar cualquier nombre, como “geoespacial”, y seleccionar Python 3.x como el paquete principal.
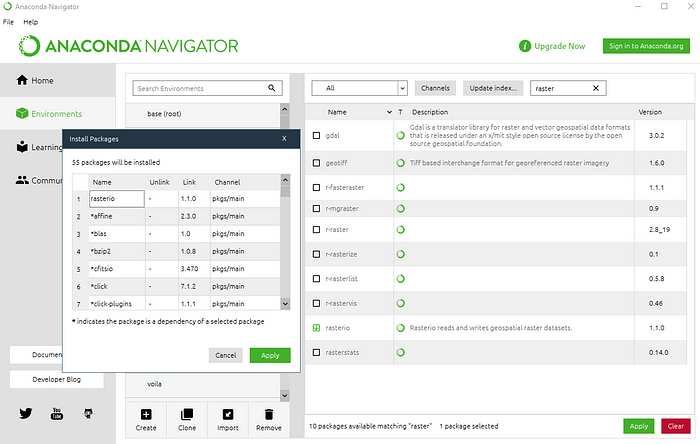
Para instalar un nuevo paquete, es necesario buscar el nombre del paquete deseado usando la barra de búsqueda (no olvides seleccionar Todos (All) en el cuadro desplegable), seleccionar el paquete de la lista y hacer clic en Aplicar (Apply). Dado que los paquetes funcionan con dependencias, dependiendo del paquete a instalar, se instalarán todos los paquetes necesarios que aún no existan en el entorno actual.
Si tiene instalado Miniconda (o tambien puede realizarse bajo el ambiente Anaconda) debe entonces dirigirse a la linea de comandos con la tecla Windows + R, o en start buscar por cmd. De click y se abrirá el command prompt. Utilice el siguiente comando para activar Conda.
Conda activate
Este comando lo dirige al ambiente base. Para crear un ambiente llamado “geo” donde instalará sus paquetes utilice el siguiente comando:
conda create --name geo
En realidad puede darle el nombre al ambiente que prefiera. Para activar el ambiente creado utilice:
conda activate geo
Ya le debe aparecer el command prompt pero en el ambiente geo. Para instalar las librerias que desee en este utilice el comando:
conda install -c conda-forge pandas
o para utilizar el gestor PIP:
pip install conda
Jupyter Lab#
La principal herramienta computacional que utilizarás durante este curso es Jupyter Lab. Jupyter Lab es una interfaz web interactiva para el desarrollo de código, que sigue el concepto conocido como REPL (Read — Evaluate — Print — Loop), el cual es ampliamente utilizado por los científicos de datos. La gran ventaja de usar un entorno REPL es que podemos desarrollar nuestro código de manera gradual, ejecutando comando por comando y verificando sus resultados. Además, podemos mantener el texto explicativo junto con el código que vamos a desarrollar y también ver los resultados, todo en el mismo entorno sin necesidad de alternar entre la línea de comandos y otras aplicaciones, como un visor de imágenes u otros. Los notebooks son una forma conveniente de entrelazar texto, código y la salida que produce en un solo archivo que luego puedes compartir, editar y modificar. Puedes pensar en los notebooks como el documento Word de los Científicos de Datos.
Un notebook comprende un solo archivo que almacena texto narrativo, código de computadora y la salida producida por dicho código. Almacenar tanto el trabajo narrativo como el computacional en un solo archivo significa que todo el flujo de trabajo puede ser registrado y documentado en el mismo lugar, sin tener que recurrir a dispositivos adicionales (como un cuaderno en papel). Una segunda característica de los notebooks es que permiten el trabajo interactivo. El trabajo computacional moderno se beneficia de la capacidad de probar, fallar, ajustar e iterar rápidamente hasta encontrar una solución funcional. Los notebooks encarnan esta cualidad y permiten al usuario trabajar de manera interactiva. Ya sea que el cálculo se realice en una laptop o en un centro de datos, los notebooks proporcionan la misma interfaz para la computación interactiva, reduciendo la carga cognitiva necesaria para escalar. En tercer lugar, los notebooks tienen interoperabilidad incorporada. El formato de notebook está diseñado para registrar y compartir el trabajo computacional, pero no necesariamente para otras etapas del ciclo de investigación. Para ampliar el rango de posibilidades y aplicaciones, los notebooks están diseñados para ser fácilmente convertibles a otros formatos. Por ejemplo, mientras que se requiere una aplicación específica para abrir y editar la mayoría de los formatos de archivos de notebook, no se necesita software adicional para convertirlos en archivos pdf que pueden ser leídos, impresos y anotados sin la necesidad de software técnico.
Un notebook de Jupyter es un archivo de texto plano con la extensión .ipynb, lo que significa que es un archivo fácil de mover, sincronizar y rastrear con el tiempo. Internamente, está estructurado como un documento de texto plano que contiene JavaScript Object Notation, que registra el estado del notebook, por lo que también se integran bien con una gran cantidad de tecnologías web modernas. El elemento atómico que forma un notebook se llama celda. Las celdas son fragmentos consistentes de contenido que contienen texto o código. De hecho, un notebook se puede considerar como una colección ordenada de celdas. Las celdas pueden ser de dos tipos: texto y código.
Jupyter Lab es una evolución de Jupyter Notebook, con algunas funcionalidades adicionales. Para trabajar en Jupyter Lab desde Anaconda debemos seleccionar el entorno con el cual deseamos trabajar y volver a la pantalla principal (Home) y hacer clic en Instalar (Install), justo debajo del ícono de Jupyter Lab.
Para trabajar desde Miniconda se debe instalar primero Jupyter Lab desde la linea de comando dentro del entorno deseado:
pip install -c conda-forge jupyterlab
Una vez completada la instalación, podemos verificar que Jupyter Notebook se haya instalado correctamente ejecutando jupyter lab desde la línea de comandos. Esto iniciará el servidor Jupyter Notebook, imprimirá información sobre el servidor en la consola y abrirá una nueva pestaña en el navegador en http://localhost:8888.
jupyter lab

Adicionar el entorno a Jupyter Lab#
Para tener disponible los entornos dentro de Jupyter Lab es necesario realizar el siguiente procedimiento. Primero instalar “ipykernel”:
pip install --user ipykernel
Luego adicionar el entorno virtual a Jupyter de la siguiente manera, donde “myenv” corresponde al nombre del entorno o ambiente:
python -m ipykernel install --user --name=myenv
Para obtener un listado de los entornos se puede utilizar la siguiente función:
jupyter kernelspec list
Y para borrar un entorno de Jupyter se utiliza:
jupyter kernelspec uninstall myenv
Otra forma de asegurarse que instalando librerías desde el Jupyter Notebook queden instaladas efectivamente en el ambiente o entorno de trabajo es:
!{sys.executable} -m pip install NombreLibreria
Contenedor Docker#
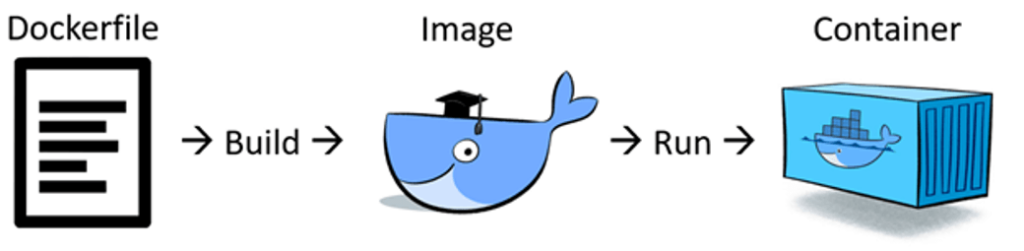
Los contenedores son una versión ligera de una máquina virtual, que es un programa que permite ejecutar un sistema operativo completo compartimentado sobre otro sistema operativo. Los contenedores permiten encapsular un entorno completo (o plataforma) en un formato que es fácil de transferir y reproducir en una variedad de contextos computacionales. La tecnología más popular para contenedores hoy en día es Docker, y las oportunidades que proporciona para construir infraestructuras transparentes y transferibles para la ciencia de datos están comenzando a explorarse.
Docker nos permite crear un “contenedor” que incluye todas las herramientas necesarias para acceder al contenido del libro de forma interactiva. Pero, ¿qué es exactamente un contenedor? Hay varias formas de describirlo, desde las más técnicas hasta las más intuitivas. En este contexto, nos centraremos en una comprensión general más que en los detalles técnicos detrás de su funcionamiento. Se puede pensar en un contenedor como una “caja” que incluye todo lo necesario para ejecutar un conjunto determinado de software. Esta caja se puede mover de una máquina a otra, y los cálculos que ejecuta seguirán siendo exactamente los mismos. De hecho, el contenido de la caja permanece exactamente igual, bit por bit. Cuando descargamos un contenedor en una computadora, ya sea una laptop o un centro de datos, no estamos instalando el software que contiene a través de los canales habituales para la plataforma en la que vamos a ejecutarlo. En su lugar, estamos descargando el software en la forma en que se instaló cuando el contenedor se construyó y empaquetó originalmente, y para el sistema operativo que también se empaquetó originalmente. Esta es la verdadera ventaja: construir una vez, ejecutar en cualquier lugar. Para los lectores con experiencia, esto podría sonar muy parecido a las máquinas virtuales. Aunque hay similitudes entre ambas tecnologías, los contenedores son más livianos y se pueden ejecutar mucho más rápido que las máquinas virtuales. Esta caja aislada interactúa con el resto de la computadora a través de varios enlaces que conectan ambos. En el caso de este libro, dado que JupyterLab es una aplicación cliente-servidor, el servidor se ejecuta dentro del contenedor y nos conectamos a él a través de dos “puertas” principales: una, a través del navegador, accederemos a la interfaz principal de Lab; y dos, “montaremos” una carpeta dentro del contenedor para poder usar el software del contenedor para editar archivos que están almacenados externamente en la máquina host.
Este es el enfoque recomendado si cumples con los siguientes requisitos:
Tienes derechos de administrador sobre tu máquina
Estás ejecutando Windows 10 Pro, macOS o Linux
En ese caso, Docker es la alternativa preferida. Proporciona una plataforma estable para ejecutar configuraciones de software complejas como la requerida en este contexto. Docker es una tecnología de contenedorización que permite ejecutar software preempaquetado (contenedorizado) en entornos controlados. Con Docker, el proyecto gds_env proporciona una plataforma contenedorizada para la Ciencia de Datos Geográficos.
Los pasos para instalar esto (si cumples con los requisitos anteriores) incluyen:
Obtener una copia de Docker e instalarla:
Windows 10 Pro/Enterprise: Instalar Docker Desktop para Windows
macOS: Empezar con Docker Desktop para Mac
Abrir una terminal o shell. Cómo hacerlo dependerá de tu sistema operativo:
Windows: recomendamos PowerShell. Escribe “PowerShell” en el menú de inicio y, cuando aparezca, presiona enter. Esto abrirá una terminal para ti.
macOS: usa Terminal.app. Puedes encontrarla en la carpeta Aplicaciones, dentro de la subcarpeta Utilidades.
Linux: si estás usando Linux, probablemente ya tengas una aplicación de terminal de preferencia. Casi cualquier distribución de Linux viene con una terminal o shell integrada.
Descargar o “pull” nuestro contenedor. Para esto, ejecuta en la terminal el siguiente comando:
docker pull darribas/gds:3.0
Una vez que el comando anterior haya terminado de instalar tu stack GDS, ¡ya estás listo para comenzar! Para iniciar una sesión de Jupyter, sigue estos pasos:
Ejecuta en la misma terminal el siguiente comando:
docker run --rm -ti -p 8888:8888 -v {PWD}:/home/jovyan/work darribas/gds:3.0
docker run: Docker hace muchas cosas, para comunicar que queremos ejecutar un nuevo contenedor, necesitamos especificarlo.
–rm: esta bandera asegura que el contenedor se elimine cuando lo cierres. Esto garantiza que cada vez que lo ejecutes nuevamente, comiences desde cero con la misma configuración exacta.
ti: esta bandera asegura además que el contenedor no se ejecute en segundo plano, sino en un modo _i_nteractivo.
p 8888:8888: con esto, nos aseguramos de redirigir el puerto desde el interior del contenedor hacia la máquina host (es decir, tu laptop). Este paso es crucial porque nos permite interactuar con el servidor y que Jupyter “envíe” JupyterLab para que podamos acceder a él en nuestro navegador web.
v {PWD}:/home/jovyan/work: de manera similar, esta bandera “monta” la carpeta desde donde se está ejecutando el comando en la terminal ({PWD}) dentro del contenedor para que sea visible y editable desde dentro del contenedor. Esta carpeta estará disponible en la carpeta de trabajo del contenedor.
gdsbook/stack: finalmente, también necesitamos especificar qué imagen queremos ejecutar. En este caso, ejecutamos la imagen creada para este libro.
Esto iniciará una sesión de Python. No cierres la ventana hasta que hayas terminado de usar Python.
Abre tu navegador favorito (preferiblemente Firefox o Chrome) y apunta a localhost:8888
Se te pedirá una contraseña o un token. Para acceder al lab, copia el token desde la terminal, ingrésalo en el cuadro y haz clic en “Iniciar sesión”.
Google Earth Engine (GEE)#
Google Earth Engine (GEE) es una plataforma basada en la nube que permite el análisis científico y la visualización a gran escala de conjuntos de datos geoespaciales. GEE fue lanzado en 2010 por Google como un sistema propietario. Actualmente, está disponible para los usuarios como un servicio gratuito para cargas de trabajo pequeñas y medianas, utilizando un modelo de negocio similar a otros servicios basados en la nube de la compañía.
Esta plataforma está construida a partir de una colección de tecnologías disponibles en la infraestructura de Google, como el sistema de gestión de clústeres informáticos a gran escala (Borg), las bases de datos distribuidas (Bigtable y Spanner), el sistema de archivos distribuido (Colossus) y el marco de ejecución de canalizaciones paralelas FlumeJava.
Google Earth Engine permite a los usuarios ejecutar algoritmos en imágenes y vectores georreferenciados almacenados en la infraestructura de Google. La API de Google Earth Engine proporciona una biblioteca de funciones que se pueden aplicar a los datos para su visualización y análisis. El catálogo de datos públicos de Earth Engine contiene una gran cantidad de imágenes y conjuntos de datos vectoriales disponibles públicamente. También se pueden crear activos privados en las carpetas personales de los usuarios.
GEE proporciona un catálogo de datos que almacena un gran repositorio de datos geoespaciales, que incluye imágenes ópticas de una variedad de satélites y sistemas aéreos, variables ambientales, pronósticos meteorológicos y climáticos, cobertura terrestre, y conjuntos de datos socioeconómicos y topográficos. Antes de estar disponibles, estos conjuntos de datos se preprocesan, lo que permite un acceso eficiente y elimina muchas barreras asociadas con la gestión de datos.
GEE utiliza cuatro tipos de objetos para representar los datos que pueden ser manipulados por su API. El tipo Image representa datos ráster que pueden consistir en una o más bandas, que contienen un nombre, tipo de datos, escala y proyección. Un conjunto o una serie temporal de Imágenes está representado por el tipo ImageCollection. GEE representa los datos vectoriales a través del tipo Feature. Este tipo está representado por una geometría (punto, línea o polígono) y una lista de atributos. El tipo FeatureCollection representa grupos de Features relacionadas y proporciona funciones para manipular estos datos, como clasificación, filtrado y visualización. GEE solo ofrece interfaces de programación que admiten procesamiento basado en píxeles. El resultado de un procesamiento en GEE se puede visualizar en el IDE web o guardar en uno de tres servicios de la compañía: Drive, Cloud Storage o Assets. GEE utiliza un servidor de Tiles para hacer que los datos estén disponibles en la interfaz web de manera eficiente.
GEE proporciona una API en JavaScript y una API en Python para la gestión y el análisis de datos. Para la versión en JavaScript, también se proporciona un Entorno de Desarrollo Integrado (IDE) basado en la web, donde el usuario tiene fácil acceso a los datos disponibles, aplicaciones y visualización en tiempo real de los resultados del procesamiento. La API de Python está disponible a través de un módulo y tiene una estructura similar a su versión en JavaScript.
El Editor de Código#
El Editor de Código es un entorno interactivo para desarrollar aplicaciones en Earth Engine. El panel central proporciona un editor de código en JavaScript. Sobre el editor hay botones para guardar el script actual, ejecutarlo y limpiar el mapa. El botón Get Link genera una URL única para el script en la barra de direcciones. El mapa en el panel inferior contiene las capas añadidas por el script. En la parte superior hay un cuadro de búsqueda para conjuntos de datos y lugares. El panel izquierdo contiene ejemplos de código, tus scripts guardados, una referencia API con capacidad de búsqueda y un gestor de activos para datos privados. El panel derecho tiene un inspector para consultar el mapa, una consola de salida y un gestor para tareas de larga duración. El botón de ayuda en la parte superior derecha contiene enlaces a esta guía y otros recursos para obtener ayuda. Aprende más en la guía del Editor de Código.
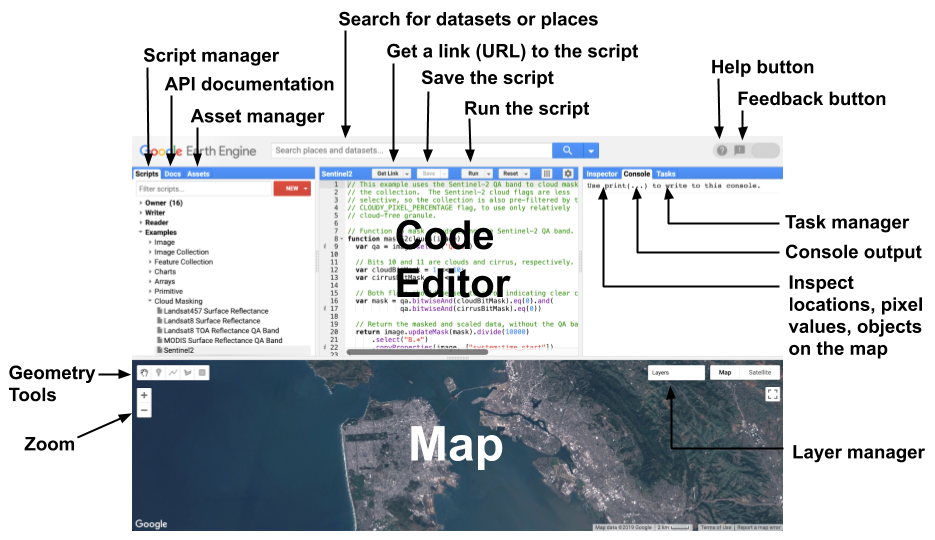
El Editor de Código de Earth Engine (EE) en code.earthengine.google.com es un IDE basado en la web para la API de JavaScript de Earth Engine. Las características del Editor de Código están diseñadas para hacer que el desarrollo de flujos de trabajo geoespaciales complejos sea rápido y fácil. El Editor de Código tiene los siguientes elementos (ilustrados en la Figura 1):
Editor de código en JavaScript
Visualización de mapas para datasets geoespaciales
Documentación de referencia API (pestaña Docs)
Gestor de scripts basado en Git (pestaña Scripts)
Consola de salida (pestaña Console)
Gestor de tareas (pestaña Tasks) para manejar consultas de larga duración
Consulta interactiva del mapa (pestaña Inspector)
Búsqueda en el archivo de datos o scripts guardados
Herramientas para dibujar geometrías
Los pasos a continuación demuestran cómo abrir Earth Engine y ejecutar un script personalizado que muestra una imagen. Para obtener los mejores resultados, es posible que desees instalar la última versión de Chrome, el navegador web de Google, disponible aquí.
Abre el Editor de Código de Earth Engine aquí: code.earthengine.google.com. Si aún no lo has hecho, necesitarás habilitar el acceso iniciando sesión con una cuenta de Google registrada.
Navega a la pestaña Scripts ubicada en la parte izquierda del Editor de Código. Allí encontrarás una colección de scripts de ejemplo que acceden, muestran y analizan datos de Earth Engine.
Bajo “Image Collection”, selecciona el ejemplo “Filtered Composite”. Verás que un script aparece en la consola central. Presiona el botón Run para ejecutar el script.
El ejemplo Filtered Composite selecciona imágenes de Landsat 7 que intersectan o están dentro de los límites de Colorado y Utah. Luego muestra un compuesto en color verdadero de las imágenes seleccionadas. Los ejemplos te introducen a métodos comúnmente usados, como filter(), clip() y Map.addLayer().
El Editor de Código tiene una variedad de características para ayudarte a aprovechar la API de Earth Engine. Visualiza scripts de ejemplo o guarda tus propios scripts en la pestaña Scripts. Consulta objetos colocados en el mapa con la pestaña Inspector. Muestra y grafica resultados numéricos utilizando la API de Google Visualization. Comparte una URL única de tu script con colaboradores y amigos usando el botón Get Link. Los scripts que desarrollas en el Editor de Código se envían a Google para su procesamiento, y las teselas del mapa generadas y/o los mensajes se envían de vuelta para mostrarse en la pestaña Map y/o Console. Todo lo que necesitas para ejecutar el Editor de Código es un navegador web (usa Google Chrome para obtener los mejores resultados) y una conexión a internet. Las siguientes secciones describen los elementos del Editor de Código de Earth Engine con más detalle.
Google Earth Engine en Python#
La API de Python de Earth Engine se distribuye como un paquete de conda-forge en: https://anaconda.org/conda-forge/earthengine-api. Se instala con el comando conda install. Sin embargo, antes de instalarla, crea un entorno conda específicamente para Earth Engine. Instalar la API de Earth Engine en su propio entorno asegura que ella y sus paquetes dependientes no causarán problemas de versiones con tu entorno base o cualquier otro entorno que hayas configurado previamente, y viceversa. Para más información sobre la gestión de entornos conda, por favor visita este sitio.
Activa tu entorno base de conda, si no está ya activado. Se recomienda crear un entorno virtual conda para la API de Earth Engine.
conda create --name ee
Activa el entorno conda ee.
conda activate ee
Para instala la API en el entorno conda ee. Asegúrate de que (ee) aparezca al principio de la línea de comandos, lo que indica que estás trabajando desde el entorno ee.
conda install -c conda-forge earthengine-api
Antes de usar la API de Earth Engine o la herramienta de línea de comandos earthengine, debes realizar una autenticación única que autorice el acceso a Earth Engine en nombre de tu cuenta de Google. Para autenticarte, utiliza el comando authenticate desde la herramienta de línea de comandos earthengine.
Dentro de tu entorno conda ee, ejecuta el siguiente comando y sigue las instrucciones que aparecen en la pantalla. Se proporcionará una URL que genera un código de autorización tras aceptar los términos. Copia el código de autorización e introdúcelo como entrada en la línea de comandos.
earthengine authenticate
Al ingresar el código de autorización, se guarda un token de autorización en un archivo de credenciales que se puede encontrar a continuación. El uso posterior del comando ee.Initialize() de la API y la herramienta de línea de comandos earthengine buscarán este archivo para autenticar. Si deseas revocar la autorización, simplemente elimina el archivo de credenciales.
ee.Initialize()
Cada vez que quieras usar ee:
import ee
ee.Initialize()
Additional sources#
Rougier, N.P., 2016. From Python to NumPy.
Oliphant, T.E., 2015. A Guide to NumPy: 2nd Edition. USA: Travis Oliphant, independent publishing.
Varoquaux, G., Gouillart, E., Vahtras, O., Haenel, V., Rougier, N.P., Gommers, R., Pedregosa, F., Jędrzejewski-Szmek, Z., Virtanen, P., Combelles, C. and Pinte, D., 2015. SciPy Lecture Notes.
Actividades#
Entorno virtual: Crea un entorno conda llamado
geoespacial_testcon Python 3.10 e instala las libreríasgeopandas,matplotlibyjupyterlab. Verifica la instalación ejecutandoimport geopandas; print(geopandas.__version__).Control de versiones: Inicializa un repositorio Git local en una carpeta de tu elección. Crea un archivo
README.mdcon una descripción breve del proyecto, realiza un commit y verifica el historial congit log.Google Earth Engine: Autentícate en GEE usando la API de Python (
earthengine-api). Ejecuta el fragmento de código de verificación de la documentación oficial para confirmar que tu entorno tiene acceso a la plataforma.Reflexión: ¿Cuáles son las ventajas y desventajas de usar un entorno Docker (como
gds_env) frente a un entorno conda local para un proyecto de análisis geoespacial? Argumenta tu respuesta considerando reproducibilidad, portabilidad y facilidad de uso.
Recursos adicionales#
Documentación oficial#
Lecturas recomendadas#
Anaconda Inc. (2023). Getting started with conda. Anaconda Documentation.
Perkel, J. M. (2018). Why Jupyter is data scientists’ computational notebook of choice. Nature, 563, 145–146.
Gorelick, N. et al. (2017). Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sensing of Environment, 202, 18–27.